こんにちは、キクです。
先日、Prometheusを用いてWebサーバの外形監視設定を行いました。
本記事では、外形監視関する設定内容や当時の調査内容を備忘録として残そうと思います。
本記事の内容
それでは、よろしくお願いします。
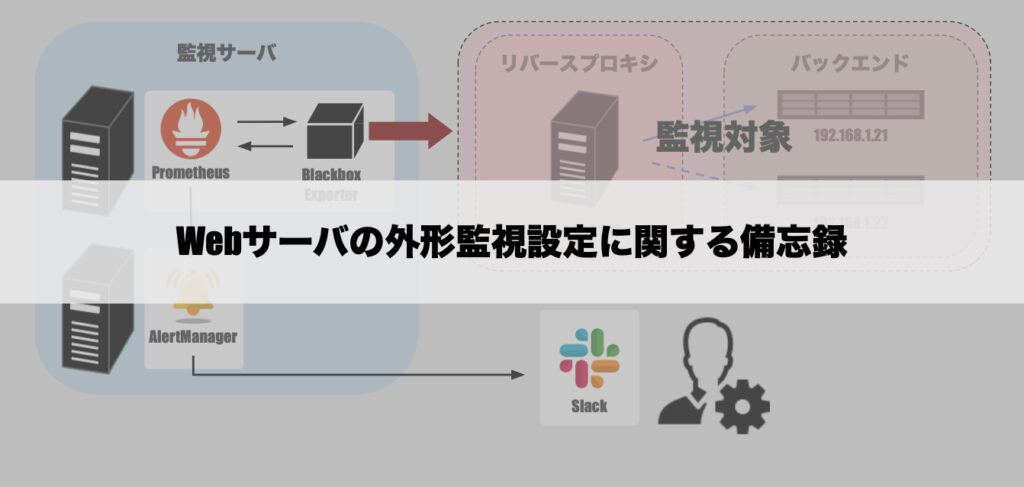
システム構成

まずは今回作業したシステム構成について簡単に触れておこうと思います。
監視ツールとしては、本記事のタイトルにもあるようにPrometheusを用いており、それに付随してAlertmanagerやblackbox_exporterなども使用してアラート発報や外形監視を行います。
また、監視対象に関する詳細は割愛しますが、以前当サイトの別記事で登場している「リバースプロキシを用いたWebサイト環境」になります。
なお、上図ではシンプルにするために冗長化されているなどの情報は省いています。
関連記事:【Linux】Nginxを用いたリバースプロキシの構築体験
外形監視とは
外形監視(別名:エンドポイント監視)とは、システムやサービスの動作状況を外部から監視し、ユーザが正常にアクセスできるかをチェックする監視のことです。
例えば、以下のような監視が含まれます。
- HTTP/HTTPS監視:Webサーバーのレスポンスコードやレスポンスタイムをチェック
- TCP/ICMP監視:指定したポートが開いているか、通信可能かを確認
- Ping監視:サーバーやネットワーク機器が応答するかを確認
- DNS監視:DNSの応答が正しく行われるかを確認
本記事の内容としては、1つ目の「HTTP/HTTPS監視」が該当します。
blackbox_exporterとは
先述の「外形監視」をPrometheusで実施しようとした場合、blackbox_exporterと呼ばれるエクスポーターが利用されることが多いです。
node_exporterのように監視対象内部の詳細なリソース情報(メトリクス)を収集するのではなく、外部からターゲットに対してリクエストを送信し、その応答内容をPrometheusに収集させるという動きになります。
例えば、以下のようなプロトコルに対応しています。
- HTTP/HTTPS プローブ:URLに対してリクエストを送り、レスポンスコードやレスポンスタイムを測定
- TCP プローブ:指定したポートに対する接続可否を確認
- ICMP (Ping) プローブ:ネットワーク接続の可用性を確認
- DNS プローブ:DNS解決が正しく行われるかを確認
プローブって何?
プローブ(Probe)は、監視や診断のために監視対象にリクエストを送信して、その応答を確認する仕組みやプロセスのことを指します。
簡単に言えば「調査のために問い合わせる行為」となります。
先述の通り様々なプローブが用意されており、各プローブに応じてリクエスト内容(監視内容)が異なっている。
よって、どのような監視をしたいかによって適切なプローブを選択することが大切となります。
作業内容
今回の作業としては、大きく以下の3ステップで進めていきます。
厳密にはさらにAlertmanagerでのアラート設定も必要になりますが、既存ではseverity(重大度)でアラートを飛ばしていることから、今回特に追加で設定することがありませんでした。
そのため、簡単に設定内容に触れる程度に留めておきます。
blackbox_exporterで利用するモジュール設定
ファイル名:/etc/prometheus/blackbox.yml(抜粋)
modules:
http_2xx:
prober: http
http:
no_follow_redirects: false
valid_status_codes: []- モジュール名は「http_2xx」として、プローブは先ほどの説明の中でも登場した「httpプローブ」を利用する
- valid_status_codesでは、正常と判定するHTTPステータスコードが指定できる
- 空の場合には「2xxステータスがすべてOK」とみなされる
Prometheusでの監視設定
まずは、対象のドメイン名とIPアドレスの紐付けをhostsファイルに追記しておきます。
ファイル名:/etc/prometheus/hosts(抜粋)
192.168.10.10 test.example.com続いて、Prometheusの設定ファイルにて実際の監視設定を追加していきます。
ファイル名:/etc/prometheus/prometheus.yml(抜粋)
scrape_configs:
- job_name: 'https-check'
scrape_interval: 15s
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
- targets: [ 'https://test.example.com:443/']
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__address__]
target_label: host
regex: 'https?://(.*):.*'
- source_labels: [__address__]
target_label: instance
- source_labels: [__address__]
target_label: module
regex: '^.*:(.*)/.*/'
- target_label: __address__
replacement: localhost:9115
- target_label: link
replacement: "true"今回のポイントとしては、先ほどblackbox_exporterで定義したモジュール「http_2xx」を指定していることと、targetsとして実際に監視を行いたいWebサイトへの接続先URLを指定していることです。
Prometheusでの簡易的な確認
上記ジョブの簡易的な動作確認として、Prometheus上で以下のPromQLを投げてみる
probe_success{job="https-check"}Element Value
probe_success{host="example.com",instance="http://example.com:443/",job="https-check",link="true",module="/"} 1probe_successの値としては「1」であるため、ジョブ自体は正常に動いていることが分かります。
また。hostラベルやinstanceラベルなど、relabel_configsで設定したラベル操作も処理できていそうなことが読み取れます。
深掘り:relabel_configsでやってること
今回の作業においては、ベースとなる既存設定がありました。
Prometheusへの理解がまだまだ浅いということもあり、正直に言うと「右へ倣え」で深く理解せずに設定を進めてしまっていました。
ただ、いい機会なので少し深掘っておこうと思います。
Prometheusのrelabel_configsは、ターゲット情報をスクレイピングする際に変更したり、メトリクスに追加するラベルを調整するための設定
①__address__を__param_targetに転用
- source_labels: [__address__]
target_label: __param_target__address__の値を__param_targetにコピーする- blackbox_exporterは
__param_targetを「target」として利用するため、最終的には監視対象URLとして扱われることになる __address__には「https://test.example.com:443/」が入るので、balckbox_exporterは以下のようなリクエストを受け取ることになる
http://localhost:9115/probe?target=https://test.example.com:443/②__address__ をhostに転用
- source_labels: [__address__]
target_label: host
regex: 'https?://(.*):.*'__address__のうち、正規表現で抽出した部分のみをhostラベルとして保存する- 正規表現で「( )」で囲まれた部分はキャプチャグループと呼ばれて抽出対象になる
- 今回の場合は「https://test.example.com:443/」の中から「test.example.com」が抽出されて
hostラベルに保存される
③__address__をinstanceに転用
- source_labels: [__address__]
target_label: instance__address__の内容をinstanceラベルとして保存するinstanceラベルは後続のアラート設定の中で利用する
④__address__をmoduleに転用
- source_labels: [__address__]
target_label: module
regex: '^.*:(.*)/.*/'__address__のうち、正規表現で抽出した部分のみをmoduleラベルとして保存する
個人的なメモ
既に触れている通り、本項目も含めてrelabel_configについては右へ倣えで設定してしまっていたが、正直な話この項目は「不適切な設定」かなと思っている
この項目により抽出されるのは「/」になるが、これがラベルとして意味を持っているとは思えない__address__の内容的には、おそらく本来抽出したかったのは「443」の部分
仮にそうだとすると、以下のようにすることで「443」を抽出することは可能
- source_labels: [__address__]
target_label: module
regex: 'https?://.*:(.*)/'ただ、処理の実態としては「/」も「443」もモジュールとしては存在しておらず、結果的には「http_2xx」が使われている
これはジョブ定義時の以下の内容が「デフォルトモジュールとしてhttp_2xxを使う」という扱いになっている模様
params:
module: [http_2xx]これは完全に推測ではあるが、今回の環境におけるmoduleラベルの操作は「使用するモジュールの選択」というよりも、ジョブの補足情報として設定している可能性が考えられる
⑤__address__をlocalhost:9115に変換
- target_label: __address__
replacement: localhost:9115__address__の値をlocalhost:9115に変換
本項目がなかった場合には、targetsにしていした「https://test.example.com:443/」に対してPrometheusから直接スクレイピングを行おうとするが、以下のような不適切なURLになってしまう
http://https://test.example.com:443/probe一方で、本項目を設定することで以下のようなリクエストがPrometheusからblackbox_exporter(localhost:9115)に対してtaget情報を連携する形でリクエストを投げるようになる
http://localhost:9115/probe?target=https://test.example.com:443/⑥linkの定義
- target_label: link
replacement: "true"linkという新しいラベルを作成して値をtrueに設定- 監視対象毎にlinkラベルを持たせることで、アラート通知時のグルーピングやフィルタリングで利用できる
Prometheusでのアラートルール定義
ファイル名:/etc/prometheus/rules/alert.rules
## 外形監視 ##
- name: https-check
rules:
- alert: https-check
expr: probe_success{job="https-check"} == 0
labels:
monitoring: "http"
severity: "CRITICAL"
annotations:
summary: '{{ $labels.instance }} *HTTP is Down*'実際のアラート通知内容はAlertmanager側での設定に依存するが、上記のルール設定の場合は概ね次のようなアラート通知が可能になる
[CRITICAL]http://test.example.com:443/ HTTP is Downこのアラートが届いたら「test.example.comのサービスが落ちたんだな」という判断に繋がる
nameとalert
今回は単体のアラート設定ということで同じ「https-check」という名前にしてしまっているが、本来は分けた方がいい模様
nameはルールグループの名前で、alertは個別のルール名という位置づけとなっている
labels
このアラートが検知された場合に付与するラベルを設定
このラベルはAlertmanager側での振り分け等で利用できる
例えば、以下のようにしてラベルの種類や値に応じて通知先(receiver)を設定できる
ファイル名:/etc/prometheus/alertmanager.yml
routes:
- match:
monitoring: http
receiver: slack-monitoring
- match:
severity: CRITICAL
receiver: slack-critical
continue: truemonitoringとしてhttpを付与されているアラート:別途定義済みのレシーバ「slack-monitoring」に通知severityとしてCRITICALを付与されているアラート:別途定義済みのレシーバ「slack-critical」に通知
continue
Alertmanagerのルート設定(route:)でアラートが複数のルートにマッチした場合に処理を継続させるためのオプション
例えば、同じアラートを複数の通知先に通知したい場合には「continue: true」にしておく
なお、デフォルトは「continue: false」である
備忘録
source_labelsとtarget_labelの違いについて
source_labelsからtarget_labelへの操作だったり、target_labelを直接操作したりとやや混乱したので整理しておきます。
| 設定 | 説明 | 例 |
|---|---|---|
source_labels | 既存のラベルの値を参照して、新しいラベルに加工する | source_labels: [__address__] を hostに転用 |
target_label | 新しいラベルを作成・変更する | target_label: __param_target で__param_targetに値をセット |
replacement | target_label に直接値を設定する | replacement: localhost:9115 で__address__ を強制的に変更 |
group_by / group_wait / group_interval
Alertmanagerでの通知設定項目
| 項目 | 説明 |
|---|---|
group_by | 同じ通知グループとしてまとめるための設定 |
group_wait | アラート検知をしてから最初の通知をするまでの待機時間 その間に同じグループのアラートを検知した場合にはまとめて通知する |
group_interval | 最初のアラートを通知して以降、同じグループの通知をまとめて送るまでの待ち時間 |