こんにちは、キクです。
先日DNSやNTPなどのインフラ系サーバの監視設定をする機会がありました。
以前Webサーバの外形監視に関して以下の記事を書きましたが、今回はインフラ系サーバのサービス監視について書いていこうと思います。
それでは、よろしくお願いします。
はじめに
まず、今回の監視環境と最終的な設定に至るまでの経緯を簡単に説明しておこうと思います。
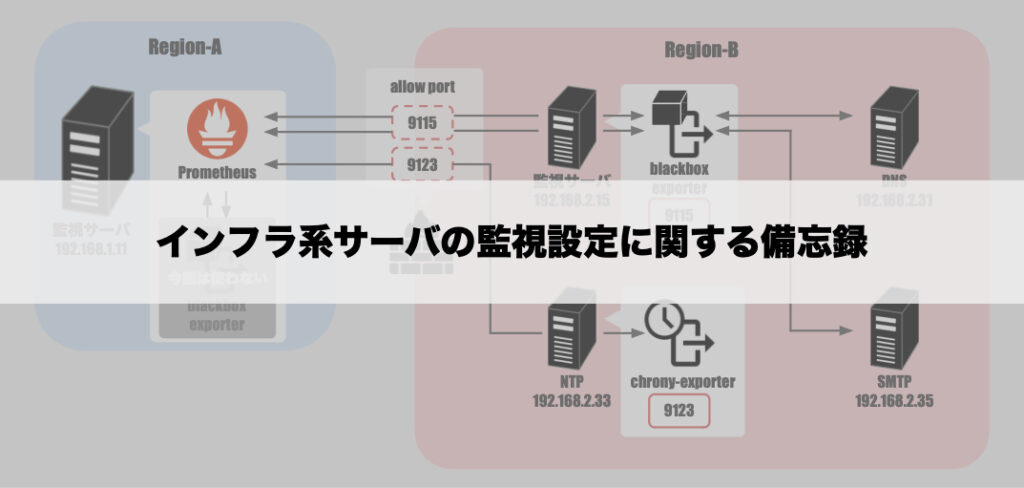
環境として、Prometheusなどの監視サービスが稼働する監視サーバと、DNSやNTPなどのインフラサービスがそれぞれ稼働するサーバ群は異なるリージョンに配置されています。
便宜上「Region-A」と「Region-B」とすると、以下のような配置になっています。
Region-A
- 監視サーバ [ ra-mon ]
- 監視ツール:Prometheus + blackbox_exporter
Region-B
- DNSサーバ [ rb-dnsXX ]
- NTPサーバ [ rb-ntpXX ]
- SMTPサーバ [ rb-smtpXX ]
Region-Bには上記インフラ系サーバ以外にもサービス提供用のサーバが稼働しており、今回の作業を実施する前からRegion-Aの監視サーバを用いて監視を行っていました。
そのため、今回は既存の監視環境を活用して新たにインフラ系サーバの監視を追加しようというのがスタートでした。
ただ、上記構成のまま監視追加するのは困難であったため、最終的にはRegion-B側に新たに監視ツールを追加する形で監視を行うことにしました。
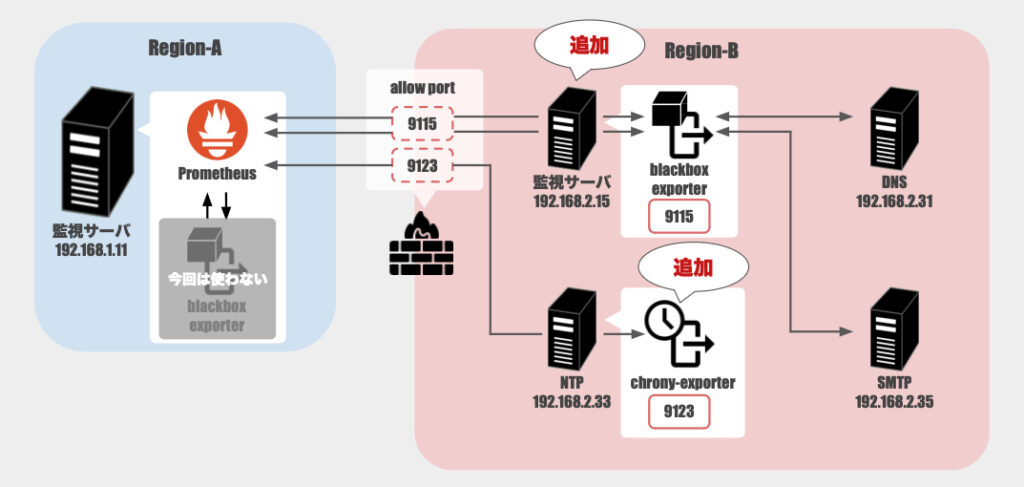
Region-A
- 監視サーバ [ ra-mon ]
- 監視ツール:Prometheus + blackbox_exporter
Region-B
- DNSサーバ [ rb-dnsXX ]
- NTPサーバ [ rb-ntpXX ]
- 監視ツール:chrony_exporter(追加)
- SMTPサーバ [ rb-smtpXX ]
- 監視サーバ [ rb-mon ](追加)
- 監視ツール:blackbox_exporter
困難であったことについては「苦労したこと」に詳細を書いています。
監視設定
それでは実際に監視設定をしていきます。
今回は以下のような流れで設定を行っていきます。
- Region-B側の監視サーバにてblackbox_exporter用のモジュール設定
- 上記モジュールを使って監視をするようにRegion-A側の監視サーバでジョブ設定
- Region-A側の監視サーバにてアラートルール設定
Region-B
まずはblackbox_exporterで利用するモジュールを定義していく
ファイル:/etc/prometheus/blackbox.yml
root@rb-mon:~# vi /etc/prometheus/blackbox.ymlmodules:
~省略~
dns:
prober: dns
timeout: 5s
dns:
query_name: "test.example.com."
query_type: "A"
valid_rcodes: [NOERROR]
preferred_ip_protocol: "ip4"
smtp_banner:
prober: tcp
timeout: 5s
tcp:
query_response:
- expect: "^220"説明
dnsモジュール
監視対象DNSサーバに「test.example.com」の名前解決要求を行う
問題なく名前解決できればDNSサービスとして正常と判断
smtp_bannerモジュール
監視対象SMTPサーバとの間にコネクションを確立させる
SMTPバナーとしてコード220(正常)が返ってくればSMTPサービスとして正常と判断
Region-A
次に、Prometheusサーバにてジョブ定義を実施する
ファイル:/etc/prometheus/prometheus.yml(抜粋)
root@ra-mon:~# vi /etc/prometheus/prometheus.yml - job_name: 'dns_check'
scrape_interval: 30s
metrics_path: /probe
params:
module: [dns]
static_configs:
- targets:
- dns01.example.com
- dns02.example.com
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 192.168.2.15:9115
- target_label: module
replacement: blackbox_exporter
- job_name: 'chrony_check'
static_configs:
- targets:
- ntp01.example.com
- ntp02.example.com
relabel_configs:
- source_labels: [__address__]
target_label: instance
- target_label: module
replacement: chrony_exporter
- job_name: 'smtp_check'
metrics_path: /probe
params:
module: [smtp_banner]
static_configs:
- targets:
- smtp01.example.com
- smtp02.example.com
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 192.168.2.15:9115
- target_label: module
replacement: blackbox_exporter最後に、アラートの発報条件等を定義していく
ファイル:/etc/prometheus/rules.yml(抜粋)
root@ra-mon:~# vi /etc/prometheus/rules.yml### Infra service monitoring ###
- name: infra_service_monitoring
rules:
- alert: dns_check
expr: probe_success{job="dns_check"} == 0
for: 5m
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }} DNS クエリを実行できません。DNS サーバーの状態を確認してください。"
- alert: chrony_check
expr: chrony_up{job="chrony_check"} == 0
for: 5m
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }} chronydのダウンを検知しました。NTP サーバーの状態を確認してください。"
- alert: smtp_check
expr: probe_success{job="smtp_check"} == 0
for: 5m
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }} にTCP接続できません。SMTP サーバーの状態を確認してください。"苦労したこと
NTP監視問題
設定し始めてから気づいたのですが、NTPはblackbox_exporterだと監視できなさそうだということ。
本監視追加対応を始めた時の調査で「おっ!DNSやSMTPはblackbox_exporterでサービス監視できるのか!」という情報を掴みました。(勘違い)
同じノリでNTPもいけると思ったのですが、僕が調べた限りはダメそうでした。
具体的には、blackbox_exporterは監視内容に応じて「prober」と呼ばれるものを使い分けますが、このProberにおいてNTP用のものが存在していませんでした。
例えば、DNSは「dns」というものが用意されており分かりやすく、SMTPも「tcp」を利用すればサービス監視を実現できます。
しかし、NTPのサービス監視用として利用できるproberがありませんでした。
そもそもなぜblackbox_exporterで監視できると思ったのかについてですが、当初ChatGPTを用いて設定の相談をしたときに「ntp proberを使えば監視できるよ」という回答でした。
そこで「お!NTPもblackbox_exporterで監視できそうだ」という勘違いが生まれました。
しかし、実際には上記の通りntp proberなるものは存在しませんでした・・・
本題とは逸れますが、ChatGPTの妄信の危険性と事実確認の大切さを学びました(笑)
今回対象のNTPサーバは「chrony」が動いているということもあり、専用のエクスポーター「chrony_exporter」を利用することにしました。
正直なところ今回の監視ではとりあえずNTPサービスが動いていることを確認できればいいので、chrony_exporterで取得できる多くの情報は使わないことにはなってしまうのですが、「NTPのサービス監視」という目的を実現するひとつの手段として採用しました。
リージョン跨ぎ問題
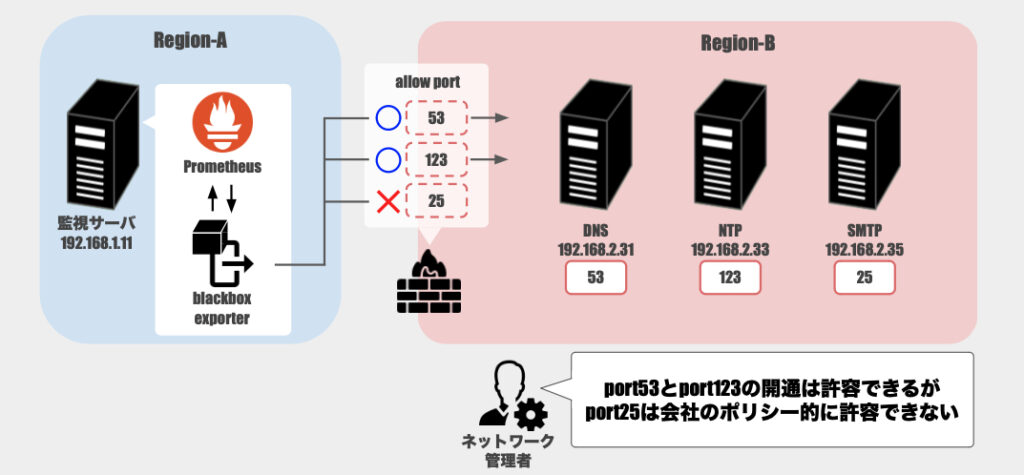
リージョンを跨る監視ということで、リージョン間にあるファイアウォールに通信が阻まれる状況が発生しました。
最初は穴開け作業に関する観点も抜け落ちていたので、監視設定の完了後に動作確認するもタイムアウトになってしまったりしてました。
調査を進めていく中で「そうか、間のファイアウォールで通信が遮られているのか」ということに気付きました。
そこでNWチームの方に相談すると一つの問題が発生。

○○は許可(allow)していいけど、○○は会社のポリシー的に通信を許可できない(deny)
具体的にはDNS(ポート53)とNTP(ポート123)は許可できるけど、SMTP(ポート25)は許可できないという環境でした。
そして最終的に取った形が、Region-Bにblackbox_exporterを配置するということ。
今回はchrony_exporterも利用しているのでリージョン間のファイアウォールとしては以下を許可してあげれば良くなりました。
- port 9115(blackbox_exporter)
- port 9123(chrony_exporter)
Region-AにあるPrometheusサーバからRegion-Bにあるblackbox_exporterやchrony_exporterを突くことで、必要な情報を取得できるようになりました。
監視ステータスと監視状態が一致しない問題
上記のリージョン跨ぎ問題において、blackbox_exporterを用いて監視するDNSやSMTPで以下のような状況が発生。
- 対象ポートがファイアウォールで拒否されているため監視用の通信が通らない
- 監視アラートとして異常を検知しない
調査してみるとアラートの設定内容が適切ではありませんでした。
例えばDNS監視のアラートについては、最終的に以下の設定にしたことは前述の通りです。
- name: infra_service_monitoring
rules:
- alert: dns_check
expr: probe_success{job="dns_check"} == 0
for: 5m
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }} DNS クエリを実行できません。DNS サーバーの状態を確認してください。"しかし、元々は以下のように設定していました。
- name: infra_service_monitoring
rules:
- alert: dns_check
expr: up{job="dns_check"} == 0
for: 5m
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }} DNS クエリを実行できません。DNS サーバーの状態を確認してください。"ほとんど同じですが、expr部分だけが異なります。
元々の設定では「up」を判定の材料にしていることが分かります。
通信が通らないような状況では、以下のように「probe_success」は「0(失敗)」になります。
root@ra-mon:~# curl -v "<http://localhost:9115/probe?module=dns&target=ra-dns01.example>"
* Trying ::1:9115...
* TCP_NODELAY set
* Connected to localhost (::1) port 9115 (#0)
> GET /probe?module=dns&target=ra-dns01.example HTTP/1.1
~省略~
probe_success 0
* Connection #0 to host localhost left intactしかし、upだとprobe_successの値そのものを判定には使ってくれません。
つまりは、upを判定材料にした監視では「probe_successが1(成功)でも0(失敗)でも、その結果の取得を含む処理さえ実行できていればステータスはOK」というような解釈になってしまいます。
※厳密にはprobe_success以外にもいろいろな値を取得していますが。
これは本来の監視要件とはズレてしまうので、「up」ではなく「probe_success」の値そのものをアラートの判定材料にすることで適切に異常検知してくれるようになりました。
備忘録
SMTPの経路調査で役に立ったコマンド
失敗例
Region-Aの監視サーバからRegion-BのSMTPサーバに対して経路調査をしようとしたら失敗した例
root@ra-mon:~# # nc -v 192.168.2.35 25
nc: connect to 192.168.1.31 port 25 (tcp) failed: Connection timed outroot@ra-mon:~# mtr -T -P 25 192.168.2.35 My traceroute [v0.93]
prometheus (192.168.1.11) 2025-03-11T13:36:25+0900
Keys: Help Display mode Restart statistics Order of fields quit
Packets Pings
Host Loss% Snt Last Avg Best Wrst StDev
1. _gateway 0.0% 17 3.0 1.0 0.6 3.0 0.7
2. xx.xx.xx.x1 0.0% 17 0.5 0.5 0.4 0.6 0.0
3. xx.xx.xx.x2 0.0% 17 1.0 1.0 0.9 1.2 0.1
4. xx.xx.xx.x3 0.0% 17 1.5 2.8 1.5 7.4 1.6
5. (waiting for reply)成功例
Region-B内で実施してみると以下のとおり成功しました。
root@rb-mon:~# nc -v 192.168.2.35 25
Connection to 192.168.2.35 25 port [tcp/smtp] succeeded!
220 smtp.example.com ESMTP Postfix (Ubuntu)SMTPサーバ側ログ(/var/log/mail.log)
Mar 11 13:23:37 smtp postfix/smtpd[3196890]: connect from unknown[192.168.2.15]
Mar 11 13:23:41 smtp postfix/smtpd[3196890]: lost connection after CONNECT from unknown[192.168.2.15]
Mar 11 13:23:41 smtp postfix/smtpd[3196890]: disconnect from unknown[192.168.2.15] commands=0/0付録:chrony_exporterの導入
今回の作業で初めてchrony_exporterを導入したので、付録として導入手順を残しておきます。
本ツールはchronyが稼働するサーバ上で動かすので、NTPサーバに導入していきます。
1. chrony-exporter導入
root@rb-ntp01:~# mkdir /tmp/chrony_exporter
root@rb-ntp01:~# cd /tmp/chrony_exporter/
root@rb-ntp01:~# wget <https://github.com/SuperQ/chrony_exporter/releases/download/v0.12.0/chrony_exporter-0.12.0.linux-amd64.tar.gz>
root@rb-ntp01:~# tar -xvf chrony_exporter-0.12.0.linux-amd64.tar.gz
root@rb-ntp01:~# chmod +x chrony_exporter
root@rb-ntp01:~# mv chrony_exporter-0.12.0.linux-amd64/chrony_exporter /usr/local/bin/chrony-exporter
root@rb-ntp01:~# cd /usr/bin
root@rb-ntp01:~# ./chrony-exporter --version2. systemd設定
ファイル:/lib/systemd/system/chrony-exporter.service
root@rb-ntp01:~# vi /lib/systemd/system/chrony-exporter.service[Unit]
Description=Chrony exporter
Wants=network-online.target
After=network-online.target
[Service]
LimitNOFILE=65535
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/bin/chrony-exporter
ExecReload=/bin/kill -HUP $MAINPID
[Install]
WantedBy=multi-user.target3. サービス起動
root@rb-ntp01:~# systemctl start prometheus-chrony-exporter.serviceroot@rb-ntp01:~# ss -pantu
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
~省略~
udp UNCONN 0 0 0.0.0.0:123 0.0.0.0:* users:(("chronyd",pid=4072,fd=7))
udp UNCONN 0 0 127.0.0.1:323 0.0.0.0:* users:(("chronyd",pid=4072,fd=5))
udp UNCONN 0 0 [::1]:323 [::]:* users:(("chronyd",pid=4072,fd=6))
~省略~
tcp LISTEN 0 4096 *:9123 *:* users:(("prometheus-chro",pid=2524826,fd=3))
~省略~