こんにちは、キクです。
本記事は、僕が自己学習で学んだことをブログでアウトプットするシリーズになります。
先日Cephの学習環境をローカルに構築した際の学習記録を記事としてアップしました。
関連記事:【Ceph】学習用ローカル環境の構築に関する学習記録
その環境自体は正常に機能していたのですが、ノートPC上の仮想環境ということでそれらを一時的にパワーオフした期間がありました。
そして改めて学習で利用するためにパワーオンしたのですが、少しおかしな状態になってしまいました。
Cephノード#1において、一部サービスが正常に起動していなかったのです。
詳細は本文で触れるとして、今回は『Cephのデーモンがおかしくなった時の対応記録』について書いていこうと思います。
それでは、よろしくお願いします。
どんな状態だったか
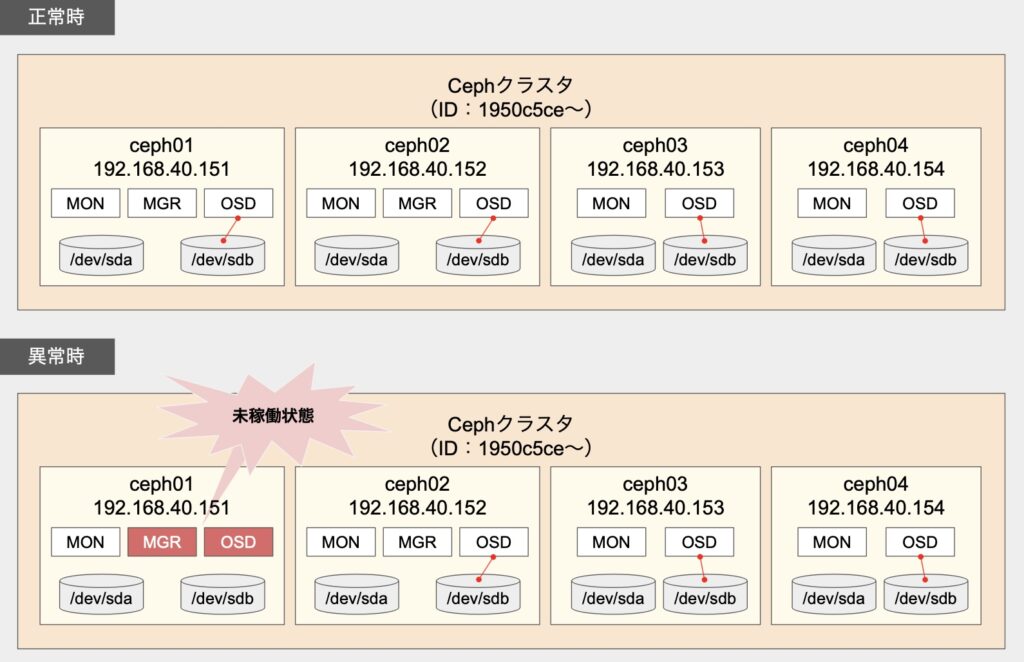
状態を確認すべく、まずは「ceph -s」コマンドを実行してみます。
root@ceph01:~# ceph -s
cluster:
id: 1950c5ce-2528-11ef-af77-c9b795315e84
health: HEALTH_WARN
2 failed cephadm daemon(s)
services:
mon: 4 daemons, quorum ceph01,ceph02,ceph03,ceph04 (age 13s)
mgr: ceph02.yqwrrm(active, since 21h)
osd: 4 osds: 3 up (since 15s), 3 in (since 15s)
data:
pools: 2 pools, 33 pgs
objects: 272 objects, 1.0 GiB
usage: 3.9 GiB used, 26 GiB / 30 GiB avail
pgs: 32 active+clean
1 active+clean+scrubbing+deep
io:
recovery: 31 MiB/s, 0 keys/s, 8 objects/sまず注目すべきは「health」が「HEALTH_WARN」になっていること。
その直下には「2 failed cephadm daemon(s)」とあります。
そして「services」においては以下2点が正常時とは異なっています。
- mgrがceph02しか起動しておらず、ceph01がいない
- osdが3/4個しか起動していない
続いてCephの各デーモンの起動状態を確認します。
root@ceph01:~# ceph orch ps
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID
alertmanager.ceph01 ceph01 *:9093,9094 running (1h) 6m ago 5d 38.5M - 0.25.0 c8568f914cd2 525cee50a8f7
crash.ceph01 ceph01 running (1h) 6m ago 5d 9308k - 17.2.7 ff4519c9e0a2 9879654ef2e6
crash.ceph02 ceph02 running (21h) 6m ago 4d 15.8M - 17.2.7 ff4519c9e0a2 4ba890994699
crash.ceph03 ceph03 running (21h) 6m ago 4d 14.1M - 17.2.7 ff4519c9e0a2 23c04123c4f3
crash.ceph04 ceph04 running (2m) 100s ago 3d 11.2M - 17.2.7 ff4519c9e0a2 3a164efb8bd0
grafana.ceph01 ceph01 *:3000 running (1h) 6m ago 5d 155M - 9.4.7 954c08fa6188 6994d3a4f98c
mgr.ceph01.ysiryi ceph01 *:9283 error 6m ago 5d - - <unknown> <unknown> <unknown>
mgr.ceph02.yqwrrm ceph02 *:8443,9283 running (21h) 6m ago 4d 516M - 17.2.7 ff4519c9e0a2 02fff62e8a13
mon.ceph01 ceph01 running (1h) 6m ago 5d 296M 2048M 17.2.7 ff4519c9e0a2 bdcefe10d825
mon.ceph02 ceph02 running (21h) 6m ago 4d 294M 2048M 17.2.7 ff4519c9e0a2 0d699543f938
mon.ceph03 ceph03 running (21h) 6m ago 4d 292M 2048M 17.2.7 ff4519c9e0a2 abd012d4d813
mon.ceph04 ceph04 running (2m) 100s ago 3d 28.1M 2048M 17.2.7 ff4519c9e0a2 2cc544bbbd57
node-exporter.ceph01 ceph01 *:9100 running (1h) 6m ago 5d 19.7M - 1.5.0 0da6a335fe13 3555efa80333
node-exporter.ceph02 ceph02 *:9100 running (21h) 6m ago 4d 19.5M - 1.5.0 0da6a335fe13 ee27547971c2
node-exporter.ceph03 ceph03 *:9100 running (21h) 6m ago 4d 19.9M - 1.5.0 0da6a335fe13 7542acb9b009
node-exporter.ceph04 ceph04 *:9100 running (2m) 100s ago 3d 6131k - 1.5.0 0da6a335fe13 8fb7b39e089d
osd.0 ceph01 error 6m ago 4d - 4096M <unknown> <unknown> <unknown>
osd.1 ceph02 running (21h) 6m ago 4d 148M 4096M 17.2.7 ff4519c9e0a2 b87e5663f01f
osd.2 ceph03 running (21h) 6m ago 4d 193M 4096M 17.2.7 ff4519c9e0a2 1b77ad294273
osd.3 ceph04 running (113s) 100s ago 3d 46.4M 4096M 17.2.7 ff4519c9e0a2 3b315a471a0a
prometheus.ceph01 ceph01 *:9095 running (1h) 6m ago 5d 123M - 2.43.0 a07b618ecd1d 76dd24559bb0先ほど「ceph -s」でおかしかったmgrとosdは「mgr.ceph01」と「osd.0」であることが分かります。
これらのデーモンは、STATUSが「error」であり、CONTAINER IDなども「unknown」になってしまっています。
「コンテナ自体がおかしいのでは?」と思ったので、コンテナ一覧も確認してみます。
root@ceph01:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
76dd24559bb0 quay.io/prometheus/prometheus:v2.43.0 "/bin/prometheus --c…" 5 hours ago Up 5 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-prometheus-ceph01
3555efa80333 quay.io/prometheus/node-exporter:v1.5.0 "/bin/node_exporter …" 5 hours ago Up 5 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-node-exporter-ceph01
6994d3a4f98c quay.io/ceph/ceph-grafana:9.4.7 "/bin/sh -c 'grafana…" 5 hours ago Up 5 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-grafana-ceph01
9879654ef2e6 quay.io/ceph/ceph "/usr/bin/ceph-crash…" 5 hours ago Up 5 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-crash-ceph01
bdcefe10d825 quay.io/ceph/ceph:v17 "/usr/bin/ceph-mon -…" 5 hours ago Up 5 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-mon-ceph01
525cee50a8f7 quay.io/prometheus/alertmanager:v0.25.0 "/bin/alertmanager -…" 5 hours ago Up 5 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-alertmanager-ceph01「なんか少ないぞ!?」となりました。
前回の記事にもある通り、Cephノード#1が正常だったときは以下の状態でした。
root@ceph01:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PRTS NAMES
2b2c873579a7 quay.io/ceph/ceph "/usr/bin/ceph-osd -…" 27 minutes ago Up 27 minutes ceph-1950c5ce-2528-11ef-af77-c9b795315e84-osd-0
eef10e64774a quay.io/prometheus/prometheus:v2.43.0 "/bin/prometheus --c…" 32 minutes ago Up 32 minutes ceph-1950c5ce-2528-11ef-af77-c9b795315e84-prometheus-ceph01
9484d20bc252 quay.io/prometheus/alertmanager:v0.25.0 "/bin/alertmanager -…" 41 minutes ago Up 41 minutes ceph-1950c5ce-2528-11ef-af77-c9b795315e84-alertmanager-ceph01
c45dfe8d158d quay.io/ceph/ceph-grafana:9.4.7 "/bin/sh -c 'grafana…" 23 hours ago Up 23 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-grafana-ceph01
a1673d9397c3 quay.io/prometheus/node-exporter:v1.5.0 "/bin/node_exporter …" 23 hours ago Up 23 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-node-exporter-ceph01
40d7774df5ed quay.io/ceph/ceph "/usr/bin/ceph-crash…" 23 hours ago Up 23 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-crash-ceph01
429e191b4f63 quay.io/ceph/ceph:v17 "/usr/bin/ceph-mgr -…" 23 hours ago Up 23 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-mgr-ceph01-ysiryi
e09da78e5911 quay.io/ceph/ceph:v17 "/usr/bin/ceph-mon -…" 23 hours ago Up 23 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-mon-ceph01なるほど、mgrとosdのコンテナそのものが存在していないということが判明。
復旧対応
1. 不具合OSDの取り外し
最初にお伝えしておくと、今回のケースでは本項目の操作は不要だった可能性があります。
ただ、実施した内容の記録として残しておこうと思います。
root@ceph01:~# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.03918 root default
-3 0.00980 host ceph01
0 hdd 0.00980 osd.0 down 0 1.00000
-5 0.00980 host ceph02
1 hdd 0.00980 osd.1 up 1.00000 1.00000
-7 0.00980 host ceph03
2 hdd 0.00980 osd.2 up 1.00000 1.00000
-9 0.00980 host ceph04
3 hdd 0.00980 osd.3 up 1.00000 1.00000root@ceph01:~# ceph osd purge 0
purged osd.0root@ceph01:~# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.02939 root default
-3 0 host ceph01
-5 0.00980 host ceph02
1 hdd 0.00980 osd.1 up 1.00000 1.00000
-7 0.00980 host ceph03
2 hdd 0.00980 osd.2 up 1.00000 1.00000
-9 0.00980 host ceph04
3 hdd 0.00980 osd.3 up 1.00000 1.00000デバイス一覧を確認
root@ceph01:~# ceph orch device ls
HOST PATH TYPE DEVICE ID SIZE AVAILABLE REFRESHED REJECT REASONS
ceph01 /dev/sdb hdd 10.0G No 10m ago Has a FileSystem, Insufficient space (<10 extents) on vgs, LVM detected
ceph02 /dev/sdb hdd 10.0G No 10m ago Has a FileSystem, Insufficient space (<10 extents) on vgs, LVM detected
ceph03 /dev/sdb hdd 10.0G No 10m ago Has a FileSystem, Insufficient space (<10 extents) on vgs, LVM detected
ceph04 /dev/sdb hdd 10.0G No 10m ago Has a FileSystem, Insufficient space (<10 extents) on vgs, LVM detected前回の学びとして「AVAILABLE」が「No」になってしまっているので、まだOSDとの繋がりがあるように思います。
試しに以下のコマンドで対象デバイスのデータを削除してみます。
root@ceph01:~# ceph orch device zap ceph01 /dev/sdb --force
zap successful for /dev/sdb on ceph01改めてデバイスの認識状態を確認します。
root@ceph01:~# ceph orch device ls
HOST PATH TYPE DEVICE ID SIZE AVAILABLE REFRESHED REJECT REASONS
ceph01 /dev/sdb hdd 10.0G Yes 2s ago
ceph02 /dev/sdb hdd 10.0G No 2m ago Has a FileSystem, Insufficient space (<10 extents) on vgs, LVM detected
ceph03 /dev/sdb hdd 10.0G No 2m ago Has a FileSystem, Insufficient space (<10 extents) on vgs, LVM detected
ceph04 /dev/sdb hdd 10.0G No 2m ago Has a FileSystem, Insufficient space (<10 extents) on vgs, LVM detectedAVAILABLEが「Yes」となり、再度利用可能な状態になったように思います。
ここで再度Cephのデーモン一覧を確認してみます。
root@ceph01:~# ceph orch ps
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID
alertmanager.ceph01 ceph01 *:9093,9094 running (1h) 2m ago 5d 37.7M - 0.25.0 c8568f914cd2 525cee50a8f7
crash.ceph01 ceph01 running (1h) 2m ago 5d 9312k - 17.2.7 ff4519c9e0a2 9879654ef2e6
crash.ceph02 ceph02 running (22h) 2m ago 4d 15.8M - 17.2.7 ff4519c9e0a2 4ba890994699
crash.ceph03 ceph03 running (22h) 2m ago 4d 14.1M - 17.2.7 ff4519c9e0a2 23c04123c4f3
crash.ceph04 ceph04 running (41m) 8m ago 3d 13.4M - 17.2.7 ff4519c9e0a2 3a164efb8bd0
grafana.ceph01 ceph01 *:3000 running (1h) 2m ago 5d 155M - 9.4.7 954c08fa6188 6994d3a4f98c
mgr.ceph01.ysiryi ceph01 *:9283 error 2m ago 5d - - <unknown> <unknown> <unknown>
mgr.ceph02.yqwrrm ceph02 *:8443,9283 running (22h) 2m ago 4d 534M - 17.2.7 ff4519c9e0a2 02fff62e8a13
mon.ceph01 ceph01 running (1h) 2m ago 5d 311M 2048M 17.2.7 ff4519c9e0a2 bdcefe10d825
mon.ceph02 ceph02 running (22h) 2m ago 4d 330M 2048M 17.2.7 ff4519c9e0a2 0d699543f938
mon.ceph03 ceph03 running (22h) 2m ago 4d 311M 2048M 17.2.7 ff4519c9e0a2 abd012d4d813
mon.ceph04 ceph04 running (41m) 8m ago 3d 79.8M 2048M 17.2.7 ff4519c9e0a2 2cc544bbbd57
node-exporter.ceph01 ceph01 *:9100 running (1h) 2m ago 5d 20.1M - 1.5.0 0da6a335fe13 3555efa80333
node-exporter.ceph02 ceph02 *:9100 running (22h) 2m ago 4d 19.7M - 1.5.0 0da6a335fe13 ee27547971c2
node-exporter.ceph03 ceph03 *:9100 running (22h) 2m ago 4d 19.7M - 1.5.0 0da6a335fe13 7542acb9b009
node-exporter.ceph04 ceph04 *:9100 running (41m) 8m ago 3d 17.0M - 1.5.0 0da6a335fe13 8fb7b39e089d
osd.0 ceph01 error 2m ago 4d - 4096M <unknown> <unknown> <unknown>
osd.1 ceph02 running (22h) 2m ago 4d 192M 4096M 17.2.7 ff4519c9e0a2 b87e5663f01f
osd.2 ceph03 running (22h) 2m ago 4d 225M 4096M 17.2.7 ff4519c9e0a2 1b77ad294273
osd.3 ceph04 running (41m) 8m ago 3d 98.7M 4096M 17.2.7 ff4519c9e0a2 3b315a471a0a
prometheus.ceph01 ceph01 *:9095 running (1h) 2m ago 5d 130M - 2.43.0 a07b618ecd1d 76dd24559bb0osdのデーモンに何かしらの変化がみられることを期待しましたが、特に変化なく「error / unknown」のままでした。
参考:6.5. Ceph OSD デプロイメントのデバイスの消去
参考:OSDの追加/削除
2. OSDの再作成
次に実施したのがosdの再作成。
まずは以下のコマンドを試してみましたが、表示結果にもあるように「既に作成済み」であると却下されてしまいました。
root@ceph01:~# ceph orch daemon add osd ceph01:/dev/sdb
Created no osd(s) on host ceph01; already created?これは先ほどデーモン一覧を確認した際に「osd.0 / error / unknown」が残っていたためと考えられます。
「生きてはいないが残骸として存在はしている」という厄介な状態とも言えると考えています。
ここで別のアプローチとして「redeploy」というものを試してみます。
root@ceph01:~# ceph orch daemon redeploy osd.0
Scheduled to redeploy osd.0 on host 'ceph01'root@ceph01:~# ceph orch ps
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID
alertmanager.ceph01 ceph01 *:9093,9094 running (2h) 10s ago 5d 37.8M - 0.25.0 c8568f914cd2 525cee50a8f7
crash.ceph01 ceph01 running (2h) 10s ago 5d 9700k - 17.2.7 ff4519c9e0a2 9879654ef2e6
crash.ceph02 ceph02 running (22h) 4m ago 4d 15.8M - 17.2.7 ff4519c9e0a2 4ba890994699
crash.ceph03 ceph03 running (22h) 4m ago 4d 14.1M - 17.2.7 ff4519c9e0a2 23c04123c4f3
crash.ceph04 ceph04 running (55m) 86s ago 3d 13.5M - 17.2.7 ff4519c9e0a2 3a164efb8bd0
grafana.ceph01 ceph01 *:3000 running (2h) 10s ago 5d 156M - 9.4.7 954c08fa6188 6994d3a4f98c
mgr.ceph01.ysiryi ceph01 *:9283 error 10s ago 5d - - <unknown> <unknown> <unknown>
mgr.ceph02.yqwrrm ceph02 *:8443,9283 running (22h) 4m ago 4d 534M - 17.2.7 ff4519c9e0a2 02fff62e8a13
mon.ceph01 ceph01 running (2h) 10s ago 5d 318M 2048M 17.2.7 ff4519c9e0a2 bdcefe10d825
mon.ceph02 ceph02 running (22h) 4m ago 4d 334M 2048M 17.2.7 ff4519c9e0a2 0d699543f938
mon.ceph03 ceph03 running (22h) 4m ago 4d 316M 2048M 17.2.7 ff4519c9e0a2 abd012d4d813
mon.ceph04 ceph04 running (55m) 86s ago 3d 88.4M 2048M 17.2.7 ff4519c9e0a2 2cc544bbbd57
node-exporter.ceph01 ceph01 *:9100 running (2h) 10s ago 5d 19.8M - 1.5.0 0da6a335fe13 3555efa80333
node-exporter.ceph02 ceph02 *:9100 running (22h) 4m ago 4d 19.7M - 1.5.0 0da6a335fe13 ee27547971c2
node-exporter.ceph03 ceph03 *:9100 running (22h) 4m ago 4d 19.4M - 1.5.0 0da6a335fe13 7542acb9b009
node-exporter.ceph04 ceph04 *:9100 running (55m) 86s ago 3d 17.0M - 1.5.0 0da6a335fe13 8fb7b39e089d
osd.0 ceph01 running (16s) 10s ago 4d - 4096M 17.2.7 ff4519c9e0a2 874d0316395a
osd.1 ceph02 running (22h) 4m ago 4d 192M 4096M 17.2.7 ff4519c9e0a2 b87e5663f01f
osd.2 ceph03 running (22h) 4m ago 4d 225M 4096M 17.2.7 ff4519c9e0a2 1b77ad294273
osd.3 ceph04 running (54m) 86s ago 3d 98.9M 4096M 17.2.7 ff4519c9e0a2 3b315a471a0a
prometheus.ceph01 ceph01 *:9095 running (2h) 10s ago 5d 126M - 2.43.0 a07b618ecd1d 76dd24559bb0osd.0が復活したように見えます。
先ほどは「daemon add」で新規作成を試みようとしましたが、既にデーモンが存在するために失敗となりました。
redeployでは既存のデーモン(osd.0)を再作成するということだと思うので、成功したものと考えられます。
その他のステータスについても確認しておきます。
root@ceph01:~# ceph -s
cluster:
id: 1950c5ce-2528-11ef-af77-c9b795315e84
health: HEALTH_WARN
1 failed cephadm daemon(s)
Degraded data redundancy: 12/816 objects degraded (1.471%), 2 pgs degraded
services:
mon: 4 daemons, quorum ceph01,ceph02,ceph03,ceph04 (age 55m)
mgr: ceph02.yqwrrm(active, since 22h)
osd: 4 osds: 4 up (since 54s), 4 in (since 54s)
data:
pools: 2 pools, 33 pgs
objects: 272 objects, 1.0 GiB
usage: 4.6 GiB used, 35 GiB / 40 GiB avail
pgs: 12/816 objects degraded (1.471%)
7/816 objects misplaced (0.858%)
29 active+clean
2 active+recovery_wait+degraded
1 active+recovering
1 active+remapped+backfill_wait
io:
recovery: 16 MiB/s, 0 keys/s, 4 objects/sosdが「4 osds 4 up」となり、ひとまず復活したように見えます。
root@ceph01:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
874d0316395a quay.io/ceph/ceph "/usr/bin/ceph-osd -…" 2 minutes ago Up 2 minutes ceph-1950c5ce-2528-11ef-af77-c9b795315e84-osd-0
76dd24559bb0 quay.io/prometheus/prometheus:v2.43.0 "/bin/prometheus --c…" 26 hours ago Up 26 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-prometheus-ceph01
3555efa80333 quay.io/prometheus/node-exporter:v1.5.0 "/bin/node_exporter …" 26 hours ago Up 26 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-node-exporter-ceph01
6994d3a4f98c quay.io/ceph/ceph-grafana:9.4.7 "/bin/sh -c 'grafana…" 26 hours ago Up 26 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-grafana-ceph01
9879654ef2e6 quay.io/ceph/ceph "/usr/bin/ceph-crash…" 26 hours ago Up 26 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-crash-ceph01
bdcefe10d825 quay.io/ceph/ceph:v17 "/usr/bin/ceph-mon -…" 26 hours ago Up 26 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-mon-ceph01
525cee50a8f7 quay.io/prometheus/alertmanager:v0.25.0 "/bin/alertmanager -…" 26 hours ago Up 26 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-alertmanager-ceph01コンテナとしても稼働していそうです。
root@ceph01:~# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.03918 root default
-3 0.00980 host ceph01
0 hdd 0.00980 osd.0 up 1.00000 1.00000
-5 0.00980 host ceph02
1 hdd 0.00980 osd.1 up 1.00000 1.00000
-7 0.00980 host ceph03
2 hdd 0.00980 osd.2 up 1.00000 1.00000
-9 0.00980 host ceph04
3 hdd 0.00980 osd.3 up 1.00000 1.00000root@ceph01:~# ceph osd df
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
0 hdd 0.00980 1.00000 10 GiB 1.1 GiB 795 MiB 0 B 290 MiB 8.9 GiB 10.60 1.01 24 up
1 hdd 0.00980 1.00000 10 GiB 994 MiB 697 MiB 2 KiB 296 MiB 9.0 GiB 9.71 0.93 23 up
2 hdd 0.00980 1.00000 10 GiB 1.1 GiB 880 MiB 2 KiB 296 MiB 8.8 GiB 11.49 1.10 28 up
3 hdd 0.00980 1.00000 10 GiB 1.0 GiB 728 MiB 2 KiB 300 MiB 9.0 GiB 10.05 0.96 24 up
TOTAL 40 GiB 4.2 GiB 3.0 GiB 7.7 KiB 1.2 GiB 36 GiB 10.46
MIN/MAX VAR: 0.93/1.10 STDDEV: 0.67デバイスとしても使えていそうなので、ひとまずOSDは復旧完了とします。
3. MGRの再作成
OSDと同じ要領でMGRについても再作成(redeploy)してみます。
root@ceph01:~# ceph orch daemon redeploy mgr.ceph01.ysiryi
Scheduled to redeploy mgr.ceph01.ysiryi on host 'ceph01'デーモンおよびコンテナの一覧を確認してみます。
root@ceph01:~# ceph orch ps
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID
alertmanager.ceph01 ceph01 *:9093,9094 running (2h) 28s ago 5d 37.9M - 0.25.0 c8568f914cd2 525cee50a8f7
crash.ceph01 ceph01 running (2h) 28s ago 5d 9704k - 17.2.7 ff4519c9e0a2 9879654ef2e6
crash.ceph02 ceph02 running (22h) 8m ago 4d 15.8M - 17.2.7 ff4519c9e0a2 4ba890994699
crash.ceph03 ceph03 running (22h) 8m ago 4d 14.1M - 17.2.7 ff4519c9e0a2 23c04123c4f3
crash.ceph04 ceph04 running (58m) 4m ago 3d 13.5M - 17.2.7 ff4519c9e0a2 3a164efb8bd0
grafana.ceph01 ceph01 *:3000 running (2h) 28s ago 5d 156M - 9.4.7 954c08fa6188 6994d3a4f98c
mgr.ceph01.ysiryi ceph01 *:8443,9283 running (38s) 28s ago 5d 40.9M - 17.2.7 ff4519c9e0a2 cc6744b4f0ea
mgr.ceph02.yqwrrm ceph02 *:8443,9283 running (22h) 8m ago 4d 534M - 17.2.7 ff4519c9e0a2 02fff62e8a13
mon.ceph01 ceph01 running (2h) 28s ago 5d 323M 2048M 17.2.7 ff4519c9e0a2 bdcefe10d825
mon.ceph02 ceph02 running (22h) 8m ago 4d 334M 2048M 17.2.7 ff4519c9e0a2 0d699543f938
mon.ceph03 ceph03 running (22h) 8m ago 4d 316M 2048M 17.2.7 ff4519c9e0a2 abd012d4d813
mon.ceph04 ceph04 running (58m) 4m ago 3d 88.4M 2048M 17.2.7 ff4519c9e0a2 2cc544bbbd57
node-exporter.ceph01 ceph01 *:9100 running (2h) 28s ago 5d 19.9M - 1.5.0 0da6a335fe13 3555efa80333
node-exporter.ceph02 ceph02 *:9100 running (22h) 8m ago 4d 19.7M - 1.5.0 0da6a335fe13 ee27547971c2
node-exporter.ceph03 ceph03 *:9100 running (22h) 8m ago 4d 19.4M - 1.5.0 0da6a335fe13 7542acb9b009
node-exporter.ceph04 ceph04 *:9100 running (58m) 4m ago 3d 17.0M - 1.5.0 0da6a335fe13 8fb7b39e089d
osd.0 ceph01 running (3m) 28s ago 4d 147M 4096M 17.2.7 ff4519c9e0a2 874d0316395a
osd.1 ceph02 running (22h) 8m ago 4d 192M 4096M 17.2.7 ff4519c9e0a2 b87e5663f01f
osd.2 ceph03 running (22h) 8m ago 4d 225M 4096M 17.2.7 ff4519c9e0a2 1b77ad294273
osd.3 ceph04 running (58m) 4m ago 3d 98.9M 4096M 17.2.7 ff4519c9e0a2 3b315a471a0a
prometheus.ceph01 ceph01 *:9095 running (2h) 28s ago 5d 128M - 2.43.0 a07b618ecd1d 76dd24559bb0root@ceph01:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
cc6744b4f0ea quay.io/ceph/ceph "/usr/bin/ceph-mgr -…" About a minute ago Up About a minute ceph-1950c5ce-2528-11ef-af77-c9b795315e84-mgr-ceph01-ysiryi
874d0316395a quay.io/ceph/ceph "/usr/bin/ceph-osd -…" 4 minutes ago Up 4 minutes ceph-1950c5ce-2528-11ef-af77-c9b795315e84-osd-0
76dd24559bb0 quay.io/prometheus/prometheus:v2.43.0 "/bin/prometheus --c…" 26 hours ago Up 26 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-prometheus-ceph01
3555efa80333 quay.io/prometheus/node-exporter:v1.5.0 "/bin/node_exporter …" 26 hours ago Up 26 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-node-exporter-ceph01
6994d3a4f98c quay.io/ceph/ceph-grafana:9.4.7 "/bin/sh -c 'grafana…" 26 hours ago Up 26 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-grafana-ceph01
9879654ef2e6 quay.io/ceph/ceph "/usr/bin/ceph-crash…" 26 hours ago Up 26 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-crash-kceph01
bdcefe10d825 quay.io/ceph/ceph:v17 "/usr/bin/ceph-mon -…" 26 hours ago Up 26 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-mon-ceph01
525cee50a8f7 quay.io/prometheus/alertmanager:v0.25.0 "/bin/alertmanager -…" 26 hours ago Up 26 hours ceph-1950c5ce-2528-11ef-af77-c9b795315e84-alertmanager-ceph01MGRのデーモンが追加され、コンテナも問題なく動いていることが分かります。
最後にステータスを確認します。
root@ceph01:~# ceph -s
cluster:
id: 1950c5ce-2528-11ef-af77-c9b795315e84
health: HEALTH_OK
services:
mon: 4 daemons, quorum ceph01,ceph02,ceph03,ceph04 (age 58m)
mgr: ceph02.yqwrrm(active, since 22h), standbys: ceph01.ysiryi
osd: 4 osds: 4 up (since 4m), 4 in (since 4m)
data:
pools: 2 pools, 33 pgs
objects: 272 objects, 1.0 GiB
usage: 4.2 GiB used, 36 GiB / 40 GiB avail
pgs: 33 active+cleanmgr一覧にceph01が追加され、healthも「HEALTH_OK」になっています。
これにて一件落着です。
付録:調査時に役立ったコマンド
本題とは若干逸れるので、今回の調査時に役に立ったコマンドを付録として残しておきます。
調査コマンド①
root@ceph01:~# ceph orch ps --service_name osd --format yaml調査コマンド②
root@ceph01:~# ceph health detail
HEALTH_WARN 2 failed cephadm daemon(s)
[WRN] CEPHADM_FAILED_DAEMON: 2 failed cephadm daemon(s)
daemon mgr.ceph01.ysiryi on ceph01 is in error state
daemon osd.0 on ceph01 is in error stateその他
GUIからも異常なのが分かる