
こんにちは、キクです。
本記事は、僕が自己学習で学んだことをブログでアウトプットするシリーズになります。
今回はCeph環境で動いている『監視系コンテナ』について書いていこうと思います。
具体的には「Grafana」「Prometheus」「Alertmanager」「Node Exporter」が稼働するコンテナです。
本記事の内容
それでは、よろしくお願いします。
はじめに
つい先月、以下の記事にあるようなCephの学習用環境をローカルに構築したというのは記憶にも新しいです。

冒頭でも触れましたが、そのCeph環境において「mon」や「osd」などCephに関するコンポーネントとは別に以下のようなツールのコンテナが自動的に作成されて稼働していました
- Grafana
- Prometheus
- Alertmanager
- Node Exporter
root@ceph01:~# ceph orch ps
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID
alertmanager.ceph01 ceph01 *:9093,9094 running (6d) 3h ago 3w 35.1M - 0.25.0 c8568f914cd2 fdd3bc627a64
crash.ceph01 ceph01 running (6d) 3h ago 3w 8716k - 17.2.7 ff4519c9e0a2 98bdff902680
crash.ceph02 ceph02 running (2m) 1s ago 3w 10.1M - 17.2.7 ff4519c9e0a2 4527c003a5bc
crash.ceph03 ceph03 running (91s) 2s ago 3w 11.0M - 17.2.7 ff4519c9e0a2 7f97de0dde37
crash.ceph04 ceph04 running (65s) 2s ago 3w 30.9M - 17.2.7 ff4519c9e0a2 3aafa6e5f19b
grafana.ceph01 ceph01 *:3000 running (6d) 3h ago 3w 163M - 9.4.7 954c08fa6188 5f781567ee65
mgr.ceph01.ysiryi ceph01 *:8443,9283 running (6d) 3h ago 3w 452M - 17.2.7 ff4519c9e0a2 9612a07f4450
mgr.ceph02.yqwrrm ceph02 *:8443,9283 running (2m) 1s ago 3w 474M - 17.2.7 ff4519c9e0a2 9dd79b00ad77
mon.ceph01 ceph01 running (6d) 3h ago 3w 427M 2048M 17.2.7 ff4519c9e0a2 feea4a0db39a
mon.ceph02 ceph02 running (2m) 1s ago 3w 38.5M 2048M 17.2.7 ff4519c9e0a2 d7bc80d6f2eb
mon.ceph03 ceph03 running (90s) 2s ago 3w 41.0M 2048M 17.2.7 ff4519c9e0a2 e4c4b74278a1
node-exporter.ceph01 ceph01 *:9100 running (6d) 3h ago 3w 21.1M - 1.5.0 0da6a335fe13 4a900911ba37
node-exporter.ceph02 ceph02 *:9100 running (2m) 1s ago 3w 7396k - 1.5.0 0da6a335fe13 afe465b01c69
node-exporter.ceph03 ceph03 *:9100 running (91s) 2s ago 3w 7384k - 1.5.0 0da6a335fe13 2fa76c26ad72
node-exporter.ceph04 ceph04 *:9100 running (65s) 2s ago 3w 7484k - 1.5.0 0da6a335fe13 e3722691ca60
osd.0 ceph01 running (6d) 3h ago 3w 184M 4096M 17.2.7 ff4519c9e0a2 ac4699ce114c
osd.1 ceph02 running (2m) 1s ago 3w 77.0M 4096M 17.2.7 ff4519c9e0a2 2d3019c6f193
osd.2 ceph03 running (74s) 2s ago 3w 79.1M 4096M 17.2.7 ff4519c9e0a2 06c962601d11
osd.3 ceph04 running (54s) 2s ago 3w 78.2M 1561M 17.2.7 ff4519c9e0a2 c4397d032917
prometheus.ceph01 ceph01 *:9095 running (6d) 3h ago 3w 166M - 2.43.0 a07b618ecd1d a0ecf7592091これらは「監視関連のツール」というのは何となく把握していたのですが、特に急ぎで必要なわけでもなかったので見て見ぬふりをしていました。
しかし、業務内で「Grafana」などのキーワードを時々耳にするようにもなってきたので、いい機会だと思い今回触りだけでも学んでみようとなりました。
ちなみに、これらのツールに関して今まで一切触れたことがないので、超基本的な部分に留まります。
各監視系コンテナについて
Grafana
オープンソースのデータ可視化および監視ツール
Cephクラスタのメトリクスを可視化するために使用される
事前設定もしくは自作したダッシュボードからCephのパフォーマンスやステータスなどをリアルタイムで監視できる
Grafanaは複数のデータソース(Prometheus,InfluxDBなど)をサポートしており、Cephメトリクスを収集するためには、通常はPrometheusを利用する
参考:PrometheusとGrafanaを組み合わせて監視用ダッシュボードを作る
Grafanaのダッシュボードには通常以下のURLで接続できる
https://CephサーバIPアドレス:3000Ceph#1より各コンテナの状況を確認すると、Ceph#1上でポート3000のGrafanaコンテナが稼働していることが分かる
root@ceph01:~# ceph orch ps
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID
~省略~
grafana.ceph01 ceph01 *:3000 running (6d) 3h ago 3w 163M - 9.4.7 954c08fa6188 5f781567ee65
~省略~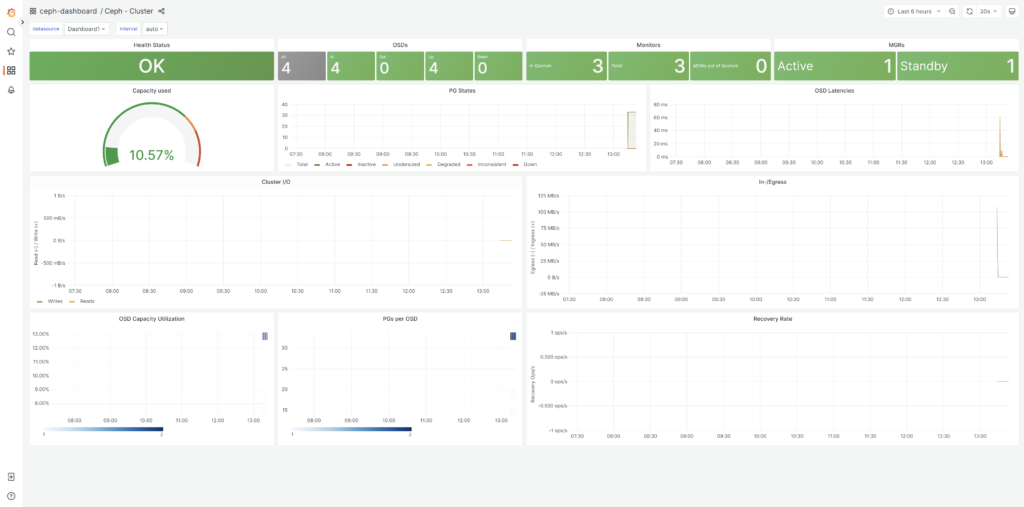
Grafana管理画面にログインできない問題
上記画面はログインしなくても確認できたが、Grafanaの特徴の一つでもある「ダッシュボード作成」はログインしないとできなさそうだった
しかし、いざデフォルトのログイン情報「admin / admin」でログインしようとするも失敗してしまう状況
加えて、grafanaコンテナ内部で確認してみるとそもそもadminが存在していない
調べてみるとgrafanaの設定ファイル「/etc/grafana/grafana.ini」の以下の部分が原因らしい
[security]
disable_initial_admin_creation = trueChatGPTを参考に、上記設定を修正してログインを試みる
root@ceph01:~# docker exec -it コンテナID /bin/sh
sh-4.4$sh-4.4$ vi /etc/grafana/grafana.ini[security]
#disable_initial_admin_creation = true
disable_initial_admin_creation = falseroot@ceph01:~# docker restart コンテナID
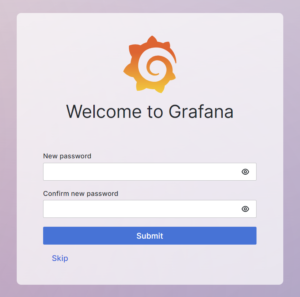
コンテナID-> デフォルトログイン情報「admin / admin」でログインできるようになった
初回ログインでパスワード変更を促された
ログインできたことでダッシュボード作成などもできるようになった
Prometheus
さまざまなシステムやアプリケーションからメトリクスを収集することが可能で、それを「時系列データベース」と呼ばれる領域に保存する
Alertmanagerと連携してアラート生成することもできる
アラート設定
Grafanaの管理画面からアラート設定を確認してみたが、確かにPrometheusが設定を持っていそうなことが分かる
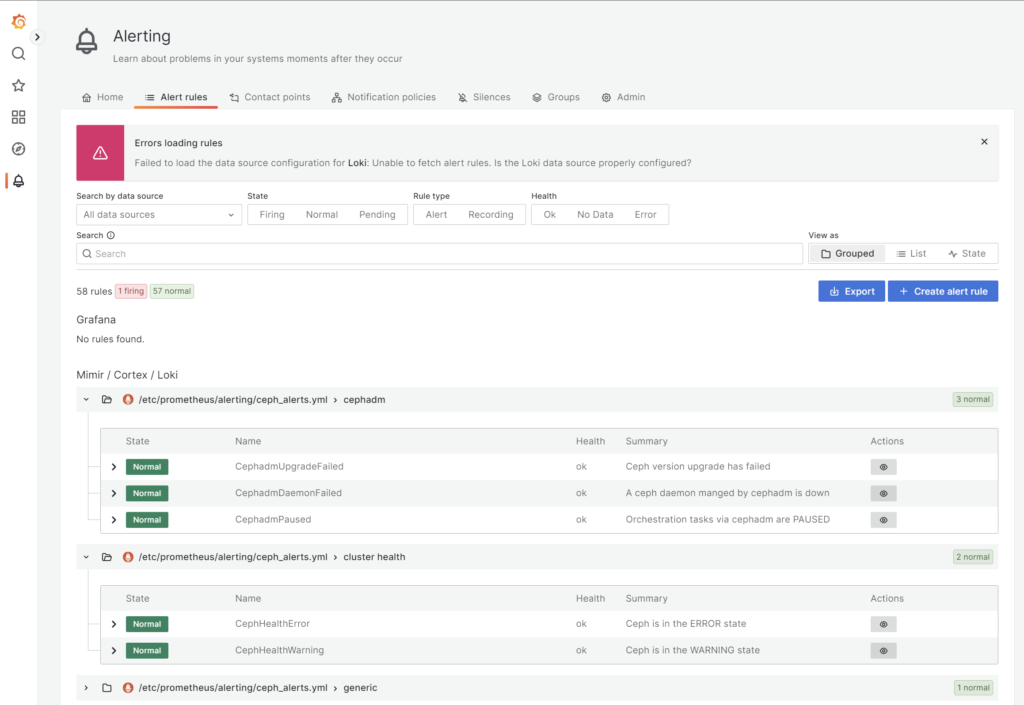
Prometheusサーバ(コンテナ)内部でも設定ファイルを確認してみる
/prometheus $ ls -al /etc/prometheus/alerting/
total 48
drwxr-xr-x 2 nobody nobody 4096 Jun 7 23:53 .
drwxr-xr-x 3 nobody nobody 4096 Jun 7 23:53 ..
-rw------- 1 nobody nobody 40075 Jun 10 01:36 ceph_alerts.yml
-rw------- 1 nobody nobody 0 Jun 10 01:36 custom_alerts.yml/prometheus $ cat /etc/prometheus/alerting/ceph_alerts.yml
groups:
- name: "cluster health"
rules:
- alert: "CephHealthError"
annotations:
description: "The cluster state has been HEALTH_ERROR for more than 5 minutes. Please check 'ceph health detail' for more information."
summary: "Ceph is in the ERROR state"
expr: "ceph_health_status == 2"
for: "5m"
labels:
oid: "1.3.6.1.4.1.50495.1.2.1.2.1"
severity: "critical"
type: "ceph_default"
- alert: "CephHealthWarning"
annotations:
description: "The cluster state has been HEALTH_WARN for more than 15 minutes. Please check 'ceph health detail' for more information."
summary: "Ceph is in the WARNING state"
expr: "ceph_health_status == 1"
for: "15m"
labels:
severity: "warning"
type: "ceph_default"
- name: "mon"
rules:
- alert: "CephMonDownQuorumAtRisk"
annotations:
description: "{{ $min := query \\"floor(count(ceph_mon_metadata) / 2) + 1\\" | first | value }}Quorum requires a majority of monitors (x {{ $min }}) to be active. Without quorum the cluster will become inoperable, affecting all services and connected clients. The following monitors are down: {{- range query \\"(ceph_mon_quorum_status == 0) + on(ceph_daemon) group_left(hostname) (ceph_mon_metadata * 0)\\" }} - {{ .Labels.ceph_daemon }} on {{ .Labels.hostname }} {{- end }}"
documentation: "<https://docs.ceph.com/en/latest/rados/operations/health-checks#mon-down>"
summary: "Monitor quorum is at risk"
~省略~-> かなり大量の設定が入っていた
疑問:GrafanaとPrometheusの役割と関係性がいまいち理解できない
PrometheusにもGUI管理画面は提供されているが、非常にシンプルであり、ダッシュボード作成やデータの可視化にはあまり適していない
グラフは確認できなかったが、以下のURLでPrometheusのGUIに接続できた
http://PrometheusサーバIPアドレス:9095
ポート9095については「ceph orch ps」で表示されたprometheusコンテナで利用しているポート
root@ceph01:~# ceph orch ps
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID
~省略~
prometheus.ceph01 ceph01 *:9095 running (108m) 9m ago 3w 127M - 2.43.0 a07b618ecd1d ef7a7cf71227※IPアドレスは実質コンテナ稼働ホストのIPアドレス(今回の場合は192.168.40.151)でOKだった
Grafanaはオープンソースの「データ可視化ツール」であり、Prometheusを含むさまざまなデータソースからメトリクスデータを取り込んで、カスタマイズ可能なダッシュボードを提供することに価値がある
また、Grafanaでもアラート作成や管理は可能であるが、この部分はPrometheus/Alertmanagerの機能で賄えているので基本的に使わない認識で良さそう
Node-Exporter
Prometheusエコシステムの一部で、サーバのメトリクスを収集するエージェント
以下のように設定が入っている
scrape_configs:
~省略~
- job_name: 'node'
static_configs:
- targets: ['ceph01:9100']
labels:
instance: 'ceph01'
- targets: ['ceph02:9100']
labels:
instance: 'ceph02'
- targets: ['ceph03:9100']
labels:
instance: 'ceph03'
- targets: ['ceph04:9100']
labels:
instance: 'ceph04'Alertmanager
Prometheusのアラートを管理するためのツール
Prometheusから送信されたアラートを受信し、それを適切なチャンネル(Email, Slack, PagerDutyなど)に通知する
アラートの集約や抑制、ルーティングも行う
利用方法(ChatGPT調べ)
- アラートルールの設定 Prometheus でアラートルールを設定し、特定の条件に基づいてアラートを発生させる
- 通知ルートの設定 Alertmanager によってアラート通知をルート設定する 例えば、Eメール、Slack、PagerDuty などの通知先を指定できる
- 抑制ルールの設定 短時間で多くのアラートが発生した場合に、重複アラートを抑制するルールを設定できる
疑問:PrometheusとAlertmanagerが連携する設定はどこで行われている?
基本的にはPrometheus側の設定ファイルで行われている
確かに以下のように設定が入っていた
/prometheus $ cat /etc/prometheus/prometheus.yml
# This file is generated by cephadm.
~省略~
alerting:
alertmanagers:
- scheme: http
static_configs:
- targets: ['ceph01:9093']
~省略~以下の通り、ceph01のalertmanagerコンテナにおいてポート9093が利用されているので、正常に連携設定が行われていそう
root@ceph01:~# ceph orch ps
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID
alertmanager.ceph01 ceph01 *:9093,9094 running (6d) 3h ago 3w 35.1M - 0.25.0 c8568f914cd2 fdd3bc627a64
~省略~