こんにちは、キクです。
以前、本ブログでSnapMirrorの基礎を紹介した記事にて以下の内容を書きました。
ブロードキャストドメインに追加するポートは、1ノードあたり最低2つ以上のポートを追加することで冗長性を高めることができる。
SnapMirror通信で利用するLIFに割り当てるロール「intercluster」ではデフォルトで「local-only」というフェイルオーバーポリシーが設定される。
そのため、1ノードあたり1ポートで構成してしまうと、LIFはパートナーノードにフェイルオーバできないので「非冗長構成」になってしまう。

本記事ではこの辺りをもう少し丁寧にご紹介できればと思います。
本記事の内容
それでは、よろしくお願いします。
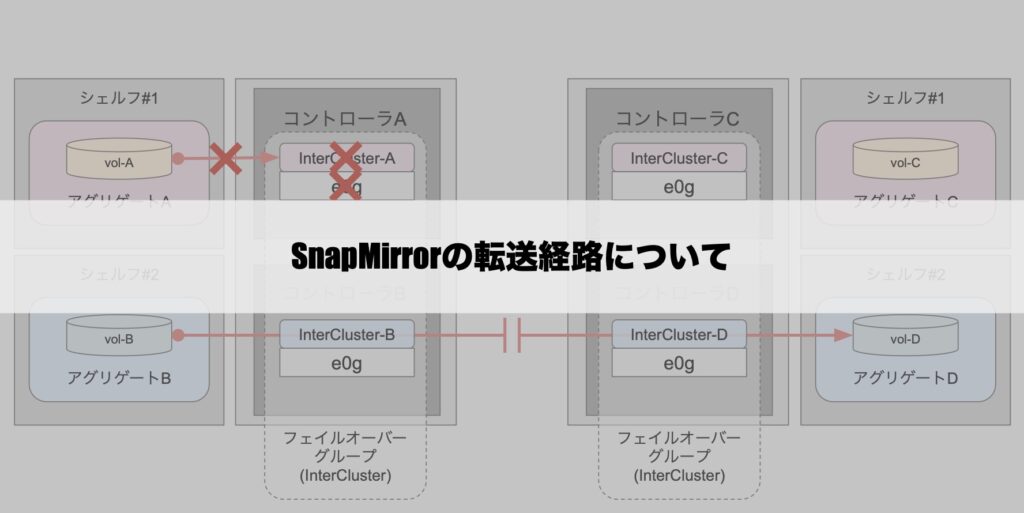
SnapMirrorの転送経路について
本項では、SnapMirrorの転送経路についてご紹介していきます。
理解してしまえば設定通りの挙動なのですが、把握していないと予期せぬ事態となる可能性があるので、参考にしていただければと思います。
僕の場合は、初期構築の動作確認テストで「予期せぬ事態」となり、そのおかげで勉強になった背景があります(笑)
通常のデータボリュームへの通信経路
SnapMirrorの転送経路と比較するために、まずは通常のデータボリュームへの通信経路についてお話します。
データボリュームをNFSボリュームとしてマウントするようなケースの場合、正常時には以下のような経路での通信となります。
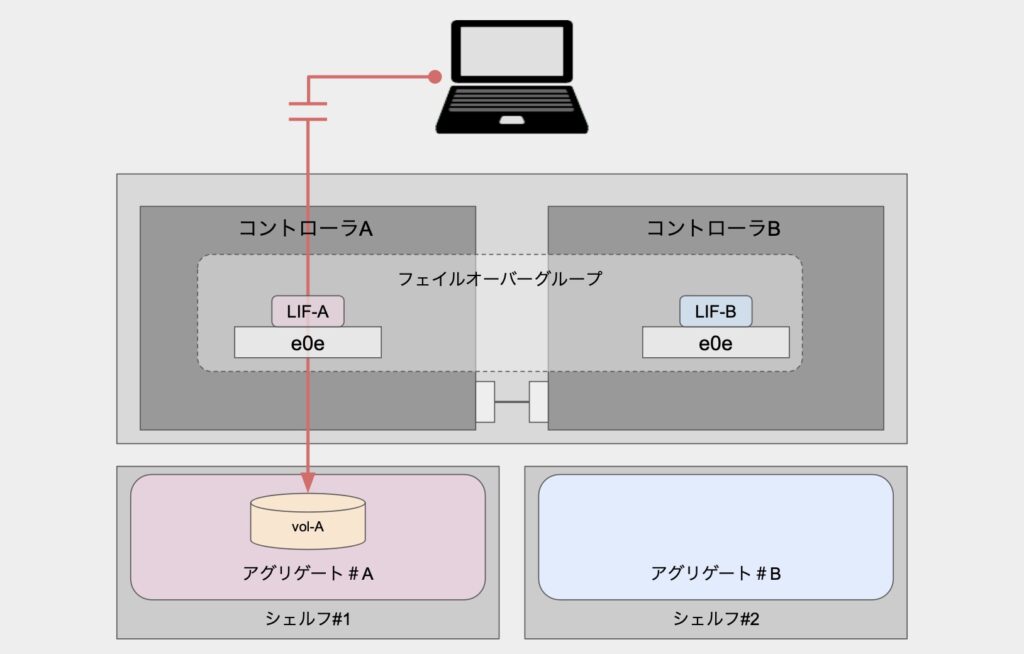
対象ボリュームには管理元であるSVMのLIFを通してアクセスしています。
正常時はLIFのホームノード側での通信となります。
次に、何らかの理由によりLIFのホームポートが利用不可となった場合の経路について見ていきます。
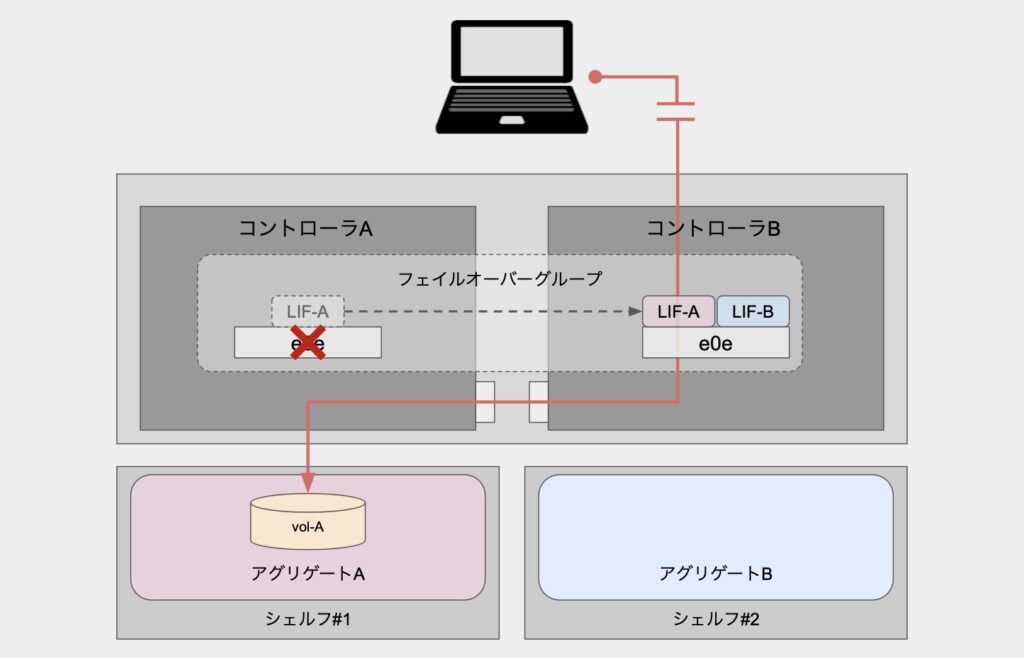
ホームポートが「利用不可」となったことでLIFのフェイルオーバーが発動し、同じフェイルオーバーグループに所属する他ノード側からアクセスしています。
このように、LIFが他ノードに移動して通信が継続されるのは、LIFのフェイルオーバーポリシーが「system-defined」などの他ノードへの移動を許容するポリシーが設定されていることが関係しています。
ちなみに、LIFにどのようなフェイルオーバーポリシーが割り当てられているかは以下のコマンドで確認できます。
::> network interface show -fields failover-policyまた、以下のコマンドでも確認することは可能で、こちらのコマンドの場合にはフェイルオーバー先となる候補のポートまで確認することができます。
::> network interface show -failoverSnapMirrorにおける通信経路
ここからは本題の「SnapMirrorにおける通信経路」についてお話していきます。
前述の「データボリュームにおけるアクセス経路」はNFSクライアントからの通信であり、SnapMirrorはNetApp内部での通信であるため、厳密には比較する対象としては適切ではないかもしれませんが、LIFの動きという観点で参考になればと思います。
最初に重要なことをお伝えすると、SnapMirrorでは対象ボリュームが所属するアグリゲートを管理するコントローラ側にあるLIFを利用して転送が行われます。
正常時には以下のような経路で転送されます。
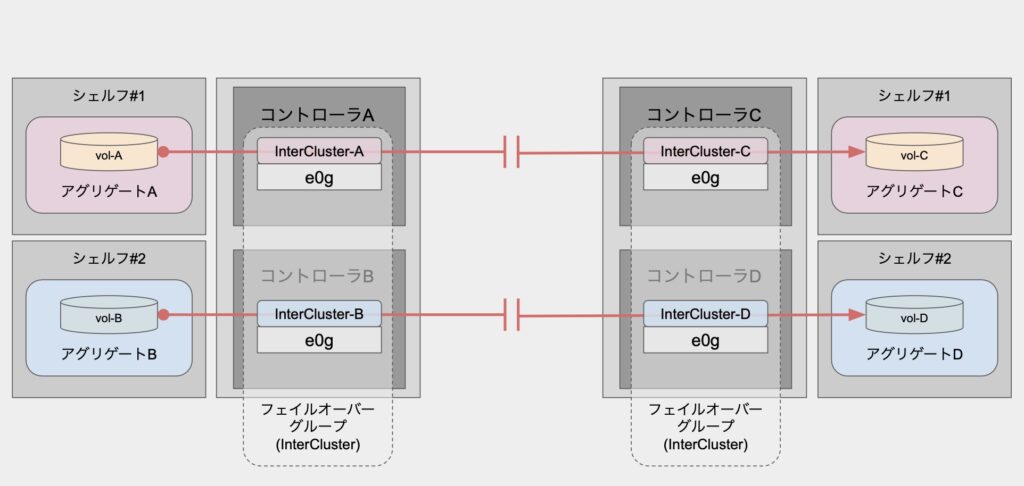
まあなんてことない経路だと思います。
しかし、先程と同様に何らかの理由によりLIFのホームポートが利用不可となった場合においては話が変わってきます。
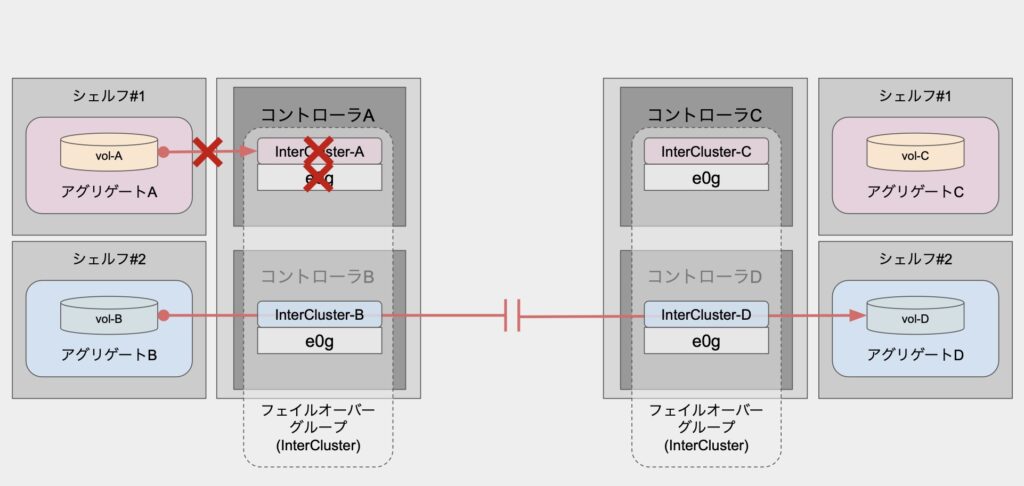
先程のデータボリュームでは、異常時にはLIFが他ノードへ移動して、そこからボリュームへのアクセスが継続されていたかと思います。
しかし、SnapMirror用のLIF(InterCluster-X)においては、ホームポートに異常が生じても他ノードへの移動(フェイルオーバー)は実施されません。
また、他ノード上にある他のSnapMirror用LIFを用いて転送が継続されるということもありません。
つまり、アグリゲートA上のボリューム「vol-A」は実質的にSnapMirrorできない状態になってしまっています。
…なんてこった。
前者の「他ノードへの移動不可」については、後述する「local-only」というフェイルオーバーポリシーが関与しています。
後者の「他経路からのSnapMirror継続不可」については、正直できない理由までは把握しきれていないのですが、おそらく「仕様」であると考えられます。
一方で、ポート障害ではなくコントローラ全体で障害が発生した場合には、また話が変わってきます。
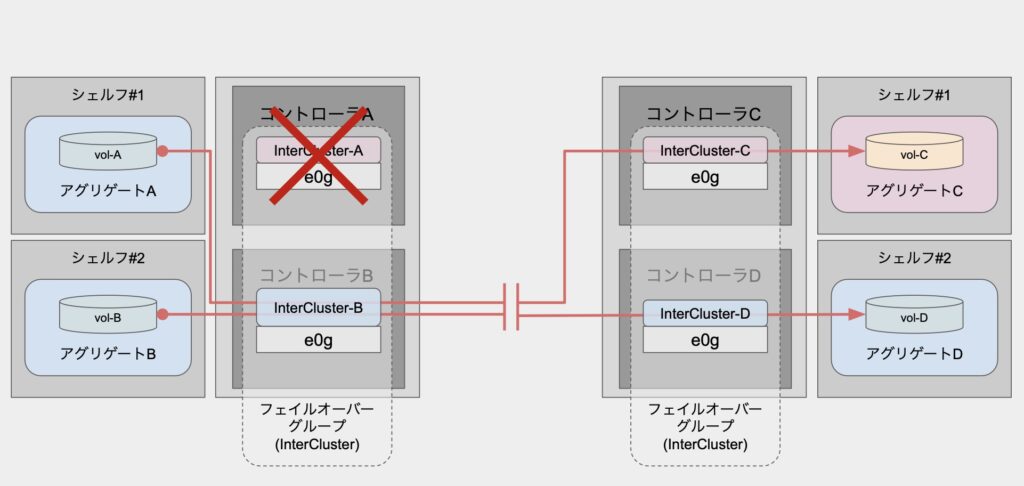
前述の「ホームポートの障害」においては、ボリューム自体の配置が変わらないため、そのままの経路で転送をしようとしていました。
しかし、コントローラ障害においてはボリュームも含めてアグリゲートの管理が他ノードに移ります。
俗に言う「テイクオーバー」の動作です。
本項の冒頭で「重要」とお伝えした内容を再掲します。
SnapMirrorでは対象ボリュームが所属するアグリゲートを管理するコントローラ側にあるLIFを利用して転送が行われる
コントローラ障害においては、テイクオーバー処理によってアグリゲートの管理が他ノードに移るため、それに伴いSnapMirrorの転送経路も他ノードに移るという点がホームポート障害とは異なっています。
補足情報
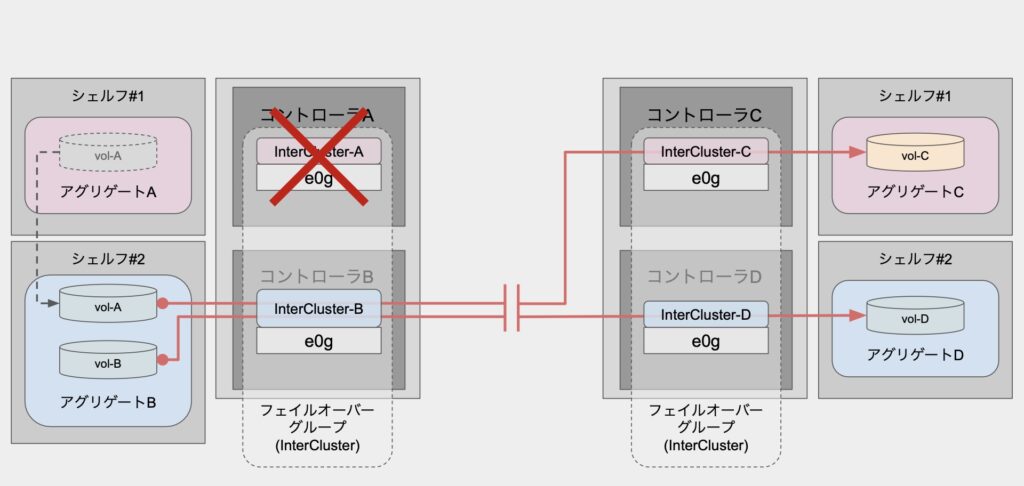
ポート障害で片コントローラの通信経路が失われている状態で新たにSnapMirrorが行われた場合、そのコントローラ上のボリュームについては懲りずに失われた経路からの転送処理が実施されます。
これはもちろん「失敗」になります。
こうなると「ポート障害が復旧するまでSnapMirrorが失敗し続けるのか?」などと考えてしまいますが、一応の回避策はあります。
本番利用中のボリュームで実施しても問題ないかは要検討事項だとは思いますが、対象ボリュームを正常なコントローラ側のアグリゲートに移動(volume move)してあげることでSnapMirrorができる状態になります。
SnapMirror経路のノード内冗長化
前項ではSnapMirrorの転送経路についてご紹介しましたが、単純なホームポート障害においては転送経路が切り替わらないということについても触れました。
本項では、そんなホームポート障害に対する対策をご紹介します。
ロール設定とフェイルオーバーポリシー
SnapMirrorにおける初期のネットワーク設定は、大きくわけて以下3つがあります。
- ブロードキャストドメインの作成
- ブロードキャストドメインへのポート追加
- LIFの作成
ブロードキャストドメイン関連の設定については次項で触れるとして、本項では先に「LIFの作成」についてお話します。
SnapMirrorで利用するLIFは以下のようなコマンドで作成します。
::> network interface create -vserver クラスタSVM名 -lif <インタークラスタLIF名> -role intercluster -home-node <コントローラ名> -home-port <ホームポート名> -address <インタークラスタLIF用IPアドレス> -netmask <サブネットマスク> -broadcast-domain <ブロードキャストドメイン名> -firewall-policy intercluster -auto-revert false[入力例]
::> network interface create -vserver cluster1 -lif intercluster1 -role intercluster -home-node cluster1-01 -home-port a0a -address 10.18.1.1 -netmask 255.255.255.0 -broadcast-domain InterCluster -firewall-policy intercluster -auto-revert false注目すべきは「-role intercluster」の部分です。
LIFのロールは目的に応じていくつか用意されており、上記ロールを割り当てたLIFは「インタークラスタLIF」と呼ばれます。
インタークラスタLIFについては公式で以下のように説明されています。
クラスタ間の通信、バックアップ、およびレプリケーションに使用されるLIF。
クラスタ ピア関係を確立するには、クラスタ内の各ノードにクラスタ間LIFを作成しておく必要があります。
インタークラスタLIFは、同じノードのLIFにのみフェイルオーバーできます。
クラスタ内の別のノードに移行またはフェイルオーバーすることはできません。
本記事で伝えたいことがマルっと書いてありますが、今回の場合は「クラスタ内の別のノードに移行またはフェイルオーバーできない」の部分が特に大切です。
この動作を制御しているのが、前述した「local-only」というフェイルオーバーポリシーになります。
「intercluster」というロールを割り当てられたLIFは、フェイルオーバーポリシーとして「local-only」が割り当てられます。
これによってインタークラスタLIFは他ノードへの移動ができなくなります。
ブロードキャストドメイン設定
以前の記事でもご紹介しましたが、SnapMirrorを利用するためのブロードキャストドメイン設定は以下のようなコマンドを実行します。
■ブロードキャストドメイン作成
[入力例]
::> broadcast-domain create -broadcast-domain InterCluster -mtu 1500 -ipspace Default■ブロードキャストドメインへのポート参加
[入力例]
::> broadcast-domain add-ports -broadcast-domain InterCluster -ports < 参加ポート(複数指定可)>今回重要なのは「冗長化するためにブロードキャストドメインにどのポートを参加させるか」ということです。
それではどのようにポートを参加させればいいのでしょうか?
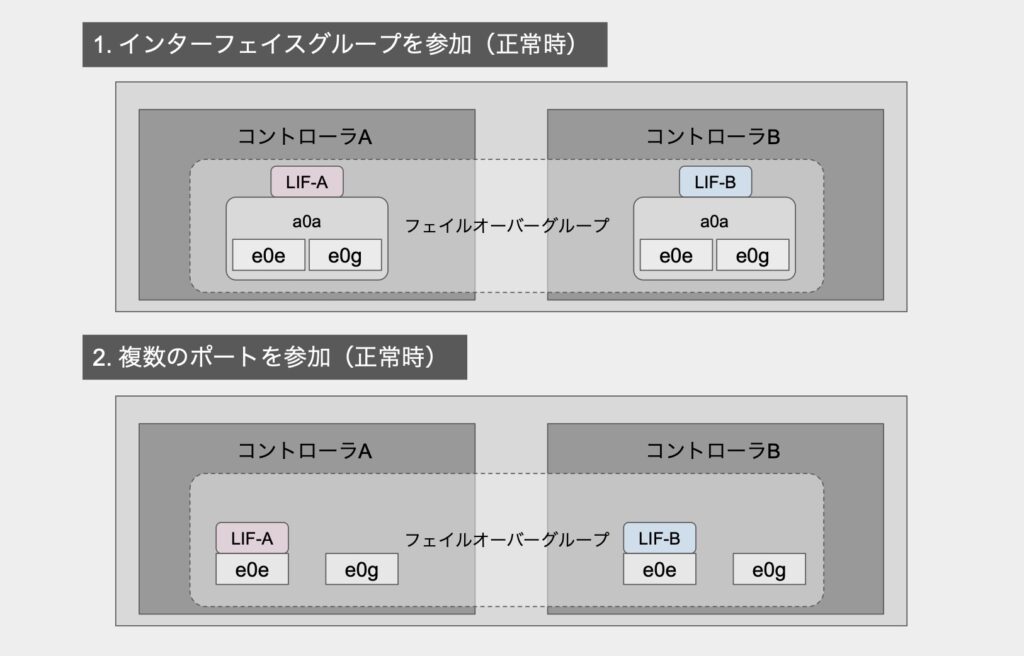
インタークラスタLIFは「他ノードへの移動」はできませんが、同じノード内での移動は可能です。
よって、冗長構成とするためには以下2パターンが考えられます(他にもあったらすみません)。
どちらも「冗長化できる」という点では同じですが、僕は前者の「複数のポートで組んだインターフェイスグループ」を用いて設することが多いです。
それぞれ設定すると以下のようになります。
また、ポート障害時にはそれぞれ以下のような挙動となります。
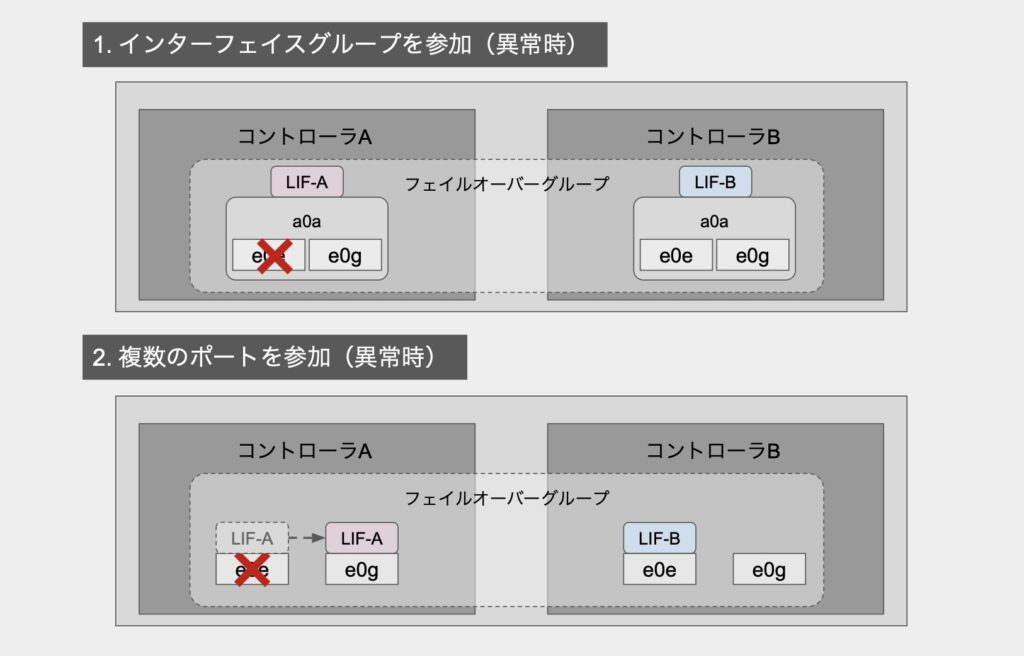
インタークラスタLIFに限らずですが、インターフェイスグループに参加しているポートで障害が発生した場合、グループ内の他のポートが正常であればLIFの移動は発生しません。
一方で、単一のポート上でインタークラスタLIFが稼働している状態でポート障害が発生した場合、インタークラスタLIFはフェイルオーバーグループ内の同一ノード上のポートに移動します。
ただし、LIFの移動は少なからずネットワーク通信への影響があるため、できることなら極力LIFの移動が発生しない構成としておきたいところです。
そうなると、複数のポートで組んだインターフェイスグループを参加させる構成の方が良いのではなかろうかと個人的には思います。
おわりに
いかがだったでしょうか。
今回はSnapMirrorの転送経路についての内容でした。
「通常のLIFと同じようにフェイルオーバーグループ内の他ノードのポートに移動できると思っていたのに、SnapMirror用のLIFは移動してくれなかった」なんてことにならないように、本記事の内容が少しでもお役に立てれば嬉しいです。
本ブログでは何度もSnapMirrorを扱っていますが、まだまだ学ぶことが多いなーと感じる技術ですね(笑)
本記事を最後まで読んでいただき、ありがとうございました。
ではでは!