こんにちは、キクです。
先日、NetAppのシェルフにてオレンジLEDが点灯していたので、その解消対応を実施しました。
本記事では、オレンジLEDの原因と対応方法についてまとめていきたいと思います。
本記事の内容
それでは、よろしくお願いします。
背景
まずはじめに、NetAppのシェルフにてオレンジLEDが点灯した背景についてご紹介します。
オレンジLEDが点灯するよりも前、対象シェルフを管理するコントローラにてONTAPのバージョンアップ作業を実施していました。
その中の作業の一環として「シェルフのF/Wバージョンアップ」を実施しており、バージョンアップ後の再起動をしたタイミングで接続している複数のシェルフのうち「ひとつだけ」がLED点灯してしまいました。
早速問い合わせを開始すると、どうやら「VPD」という内部情報が不整合状態となっていることが原因であることが分かりました。
VPDってなんぞや・・・?
VPDについて
今回の対応で初めて「VPD」というものの存在を知りました。
公式的に情報が揃っているわけではないので、今回分かった範囲で残しておこうと思います。
VPDは正式名称を「Virtual Product Data」といい、部品のシリアルなどの製品情報が記録されています。
つまり、VPDはONTAPの「内部情報」という認識で問題ないかと思います。
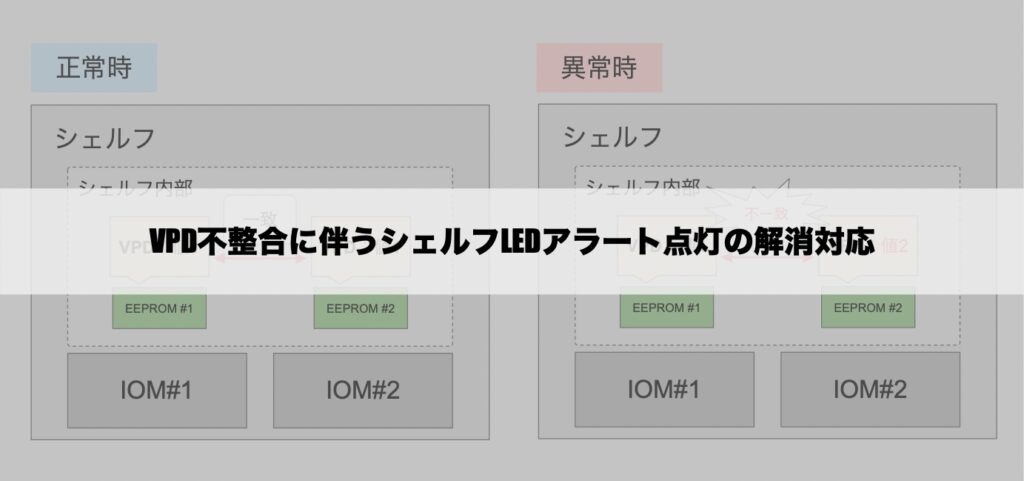
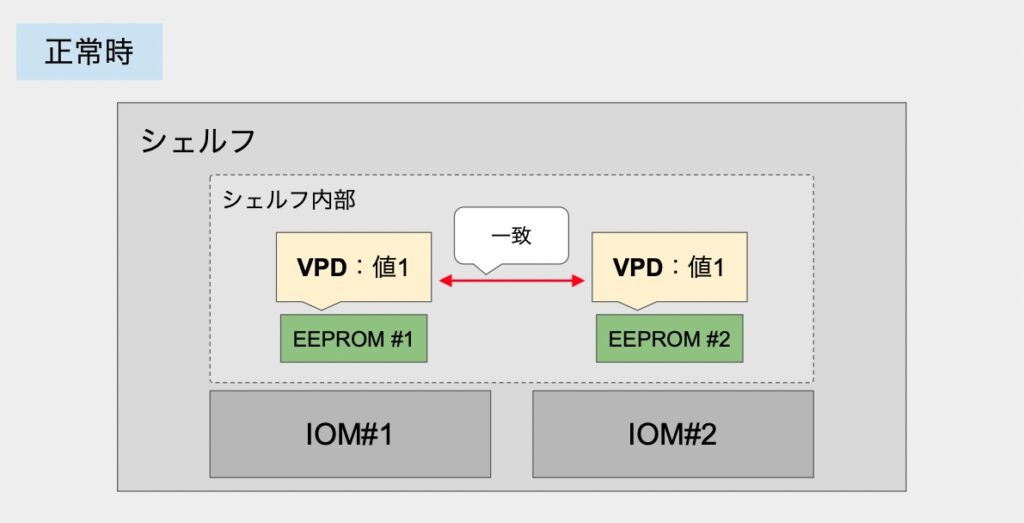
VPDの所有者としては「シェルフ」が該当します。
シェルフ内部にはEEPROMと呼ばれるパーツが2つ搭載されており、それぞれにVPD情報が記録されています。
すなわち、VPDはシェルフ毎に冗長化されているということになります。
また、VPDはシェルフに搭載されているI/Oモジュール(IOM)が読み込んで利用しますが、この「読み込みタイミング」は「IOM起動時」になります。
IOMからの読み込みでは、それぞれのVPDが一致していることを検証し、問題なければオレンジLEDが点灯することもなく起動が完了します。
つまり、今回の事象では「VPDの検証」で問題があったということになります。
原因「BUG:566789」について
今回の事象の原因は「BUG:566789」に該当していることが分かりました。
既に触れた内容と重複する部分もありますが、本バグの公式説明としては以下の通りです。
The shelf architecture is such that there are two EEPROMs containing Vital Product Data (VPD),
one on I2C bus 1 and one on I2C bus 2.
Upon boot, the I/O Module (IOM) attempts to read and verify the contents of both EEPROMs.
The EEPROMs are read successfully.However, the "Backplane VPD SEEROM corrupt or unreadable" message is still reported under the following conditions:
1. If the booting IOM detects that the calculated checksum does not match the stored checksum in the EEPROM
2. If the booting IOM detects that the contents of the EEPROMs differ from each other.参考:566789 - Invalid or mismatched VPD data causes SES error
参考:Disk shelf reports "Backplane VPD SEEROM corrupt or unreadable"※各リンク先の参照には、NetAppサポートサイトのアカウントが必要です
また、補足説明として以下の内容も記載されています。
Having redundant VPDs allows the system to continue operating when these issues are encountered.
However, the reported error should be addressed at the soonest opportunity.
The IOM only verifies VPD contents during start-of-day scenarios (reboot or power-cycle),
so this issue can remain dormant until then.参考:566789 - Invalid or mismatched VPD data causes SES error
参考:Disk shelf reports "Backplane VPD SEEROM corrupt or unreadable"※各リンク先の参照には、NetAppサポートサイトのアカウントが必要です
本バグが発動する原因としては、以下のいずれかの状態であることが考えられます。
- ハードウェア的にチップが故障している
- ソフトウェア的にチップ情報が狂っている
もしハードウェア的にチップが故障している場合には、物理的な交換が必要となります。
その際には、シェルフ丸々交換ということになるので、影響が大きそうです。
何らかの理由により、ソフトウェア的に情報が狂ってしまった場合には、以下2つの対応があります。
- IOM12のF/Wバージョンアップ(恒久対策)
- VPD情報の修正コマンドの実施(暫定対策)
作業方針
今回僕が対応したケースを整理すると、次のようになります。
バグ説明文の記載内容としては、2つ目の「起動中の IOM が 、EEPROM の内容が互いに異なることを検出した場合」に該当します。
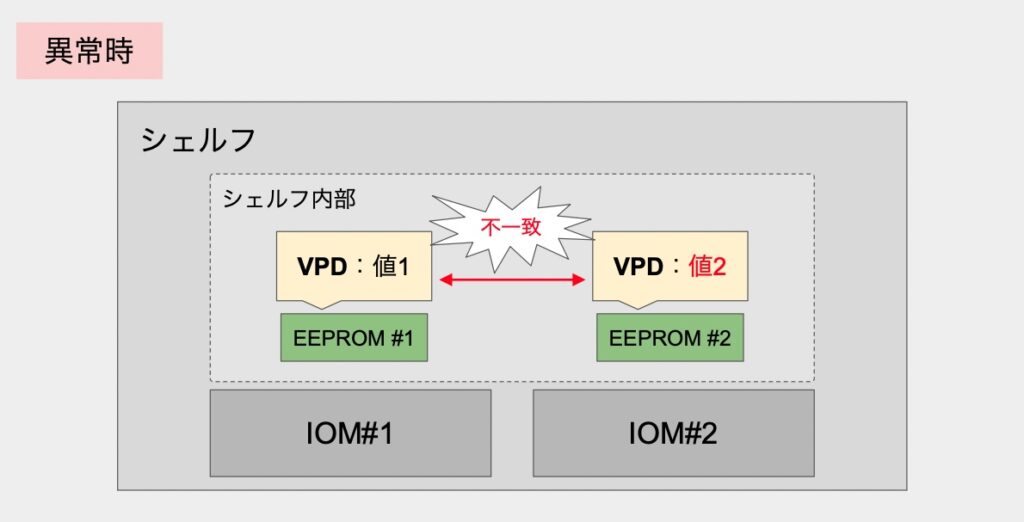
正直なところ、いつから対象シェルフのVPD情報が不整合を起こしていたのかは不明ではありますが、状況を整理すると以下のようになります。
- 何らかの理由によりVPD情報が不整合となった
- シェルフのF/Wバージョンアップ後に、IOM再起動を実施
- 各IOMにてVPD情報の読み込みおよび検証が実施される
- 不整合状態であるためオレンジLED点灯
また、修正コマンドの実施という「暫定対策」を選択した背景についても簡単に触れておきます。
本来であれば、バグが再発しないように「恒久対策」を実施するのが望ましいと思います。
しかし、IOMのF/Wバージョンアップをする場合には、該当シェルフだけでなく他のシェルフなども含めた互換性なども考慮する必要があり、影響範囲が大きくなることを懸念しました。
オレンジLED解消作業
それでは、実際の作業内容についてご紹介します。
今回の作業内容は、大きく分けて3ステップになります。
- VPD情報の修正
- 対象シェルフのIOM#1を再起動
- 対象シェルフのIOM#2を再起動
ステップ1:VPD情報の修正
事前確認
まずは事前確認作業を実施します
1. コントローラ01から各シェルフへの接続経路を確認
ClusterX::> node run -node ClusterX-01 sasadmin expander_map■確認事項
・プライマリ経路から各シェルフを認識していること
・セカンダリ経路から各シェルフを認識していること
2. コントローラ02から各シェルフへの接続経路を確認
ClusterX::> node run -node ClusterX-02 sasadmin expander_map■確認事項
・プライマリ経路から各シェルフを認識していること
・セカンダリ経路から各シェルフを認識していること
3. 各シェルフのステータスを確認
ClusterX::> storage shelf show[実行例]
Module Operatioonal
Shelf Name Shelf ID Serial Number Model Type Status
----------- --------- ---------------- -------- ------ --------------
1.1 1 xxxxxxxxxxx xxxxxx IOM12 Normal
1.2 2 xxxxxxxxxxx xxxxxx IOM12 Normal
1.3 3 xxxxxxxxxxx xxxxxx IOM12 Normal
2.1 11 xxxxxxxxxxx xxxxxx IOM12 Normal
2.2 12 xxxxxxxxxxx xxxxxx IOM12 Normal
2.3 13 xxxxxxxxxxx xxxxxx IOM12 Normal
6 entries were displayed■確認事項
・対象シェルフの「Operational Status」が「Normal」であること
4. 後続作業で使用するIOM再起動で利用可能なパスを確認
ClusterX::> node run -node ClusterX-02 acpadmin ibacp_list_all[実行例]
Number of ACP modules 12
MAC SES Last Contact Protocol Assigner Shelf Current Inband IOM shelf
Address bit (seconds ago) Version ACPA ID S/N State ID Type flag
-------- ----- ------------- --------- ---------- ---------- ------- -------- ----- -----
xxxxxx 01 xxxxxxxx 0.0.00.00 0 xxxxxx 0xd 0d.01.A IOM12 0x20
xxxxxx 01 xxxxxxxx 0.0.00.00 0 xxxxxx 0xd 0d.01.B IOM12 0x20
xxxxxx 01 xxxxxxxx 0.0.00.00 0 xxxxxx 0xd 0d.02.A IOM12 0x20
xxxxxx 01 xxxxxxxx 0.0.00.00 0 xxxxxx 0xd 0d.02.B IOM12 0x20
xxxxxx 01 xxxxxxxx 0.0.00.00 0 xxxxxx 0xd 0d.03.A IOM12 0x20
xxxxxx 01 xxxxxxxx 0.0.00.00 0 xxxxxx 0xd 0d.03.B IOM12 0x20
xxxxxx 01 xxxxxxxx 0.0.00.00 0 xxxxxx 0xd 0b.11.A IOM12 0x20
xxxxxx 01 xxxxxxxx 0.0.00.00 0 xxxxxx 0xd 0b.11.B IOM12 0x20
xxxxxx 01 xxxxxxxx 0.0.00.00 0 xxxxxx 0xd 0b.12.A IOM12 0x20
xxxxxx 01 xxxxxxxx 0.0.00.00 0 xxxxxx 0xd 0b.12.B IOM12 0x20
xxxxxx 01 xxxxxxxx 0.0.00.00 0 xxxxxx 0xd 0b.13.A IOM12 0x20
xxxxxx 01 xxxxxxxx 0.0.00.00 0 xxxxxx 0xd 0b.13.B IOM12 0x20■確認事項
・対象シェルフのInband ID「シェルフ番号.A」が表示されていること
・対象シェルフのInband ID「シェルフ番号.B」が表示されていること
VPD情報の修正
ここから実際の解消作業を実施していきます。
1. コントローラ02のノードシェル(権限:diag)への切り替え
ClusterX::> node run -node ClusterX-02
ClusterX-02> priv set diag2. 作業前のVPD情報が不一致であることを確認
ClusterX-02*> sasadmin expander_cli シェルフ番号 'vpd midplane_compare'[実行例]
Mismatch detected
VPD x1 - xxxx: xx xx xx xx xx xx xx xx xx xx xx xx xx xx xx xx
VPD x2 - xxxx: xx xx xx xx xx xx xx xx xx xx xx xx xx xx xx xx
midplane_compare test completed. There were mismatches■確認事項
・以下のように表示されること
"midplane_compare test completed. There were mismatches"
・各VPDの値が一致していないこと
3. 正常なVPD情報を異常なVPD情報側にコピー
ClusterX-02*> sasadmin expander_cli シェルフ番号 'vpd midplane_copy x1 x2'4. 再度VPD情報を比較して、不一致が修正されていることを確認
ClusterX-02*> sasadmin expander_cli シェルフ番号 'vpd midplane_compare'[実行例]
midplane_compare test completed. Both VPDs match■確認事項
・以下のように表示されること
"midplane_compare test completed. Both VPDs match"
ステップ2:対象シェルフのIOM#1を再起動
VPD情報の不整合状態は解消したので、ここからは各IOMにVPDを読み込んでもらうために再起動を行います。
なお、本作業は必ず1台ずつ実施します。
どちらが先でも問題ありませんが、今回はIOM#1(A系)から再起動していきます。
1. 再起動前のシェルフ接続経路を再確認
ClusterX-02*> sasadmin expander_map■確認事項
・プライマリ経路から各シェルフを認識していること
・セカンダリ経路から各シェルフを認識していること
2. 対象シェルフ のIOM#1を再起動(A系)
ClusterX-02*> acpadmin expander_power_cycle シェルフ番号.a
ClusterX-02*> exit3. 再起動後、動作が安定するまで「1分程度」待機
作業をやってみた感想としては、再起動コマンド実行後はすぐに安定状態となっていましたが、念のための待機時間になります。
4. A系再起動後、各シェルフのステータスを確認
ClusterX::> storage shelf show■確認事項
・対象シェルフの「Operation Status」が「Normal」であること
5. A系再起動後、コントローラ01から各シェルフへの接続経路を確認
ClusterX::> node run -node ClusterX-01 sasadmin expander_map■確認事項
・プライマリ経路から各シェルフを認識していること
・セカンダリ経路から各シェルフを認識していること
6. A系再起動後、コントローラ02から各シェルフへの接続経路を確認
ClusterX::> node run -node ClusterX-02 sasadmin expander_map■確認事項
・プライマリ経路から各シェルフを認識していること
・セカンダリ経路から各シェルフを認識していること
ステップ3:対象シェルフのIOM#2を再起動
続いてIOM#2(B系)の再起動を実施していきます。
1. コントローラBのノードシェル(権限:diag)への切り替え
ClusterX::> node run -node ClusterX-02
ClusterX-02> priv set diag2. 対象シェルフ のIOM#2を再起動(B系)
ClusterX-02*> acpadmin expander_power_cycle シェルフ番号.b
ClusterX-02*> exit3. 再起動後、動作が安定するまで「1分程度」待機
4. B系再起動後、各シェルフのステータスを確認
ClusterX-02> storage shelf show■確認事項
・対象シェルフの「Operational Status」が「Normal」であること
5. B系再起動後、コントローラ01から各シェルフへの接続経路を確認
ClusterX::> node run -node ClusterX-01 sasadmin expander_map■確認事項
・プライマリ経路から各シェルフを認識していること
・セカンダリ経路から各シェルフを認識していること
6. B系再起動後、コントローラ02から各シェルフへの接続経路を確認
ClusterX::> node run -node ClusterX-02 sasadmin expander_map■確認事項
・プライマリ経路から各シェルフを認識していること
・セカンダリ経路から各シェルフを認識していること
7. 作業後の障害状況を確認する
ClusterX::> node run -node ClusterX-02
ClusterX-02> storage show fault[実行例]
No faults found in storage subsystem■確認事項
・以下のように表示されること
"No faults found in storage subsystem"
8. 作業端末からログアウトする
ClusterX-02> exit
ClusterX::> exitおわりに
いかがだったでしょうか。
今回はシェルフのVPD情報が不整合を起こしたことに起因するオレンジLED点灯に対する解消作業についてご紹介しました。
前述の通り、今回の対応を実施するまで「VPD」というものの存在すら知りませんでしたが、またひとつ勉強になったなと感じます。
この学びが本記事を通してあなたの学びにも繋がっていれば嬉しいです。
本記事を最後まで読んでいただき、ありがとうございました。
ではでは!