
こんにちは、キクです。
先日、NetAppのOSバージョンアップに伴って発生した通信障害について紹介させていただきましたが、「VMware観点での障害情報は整理できていないな」と感じました。
本記事では、ストレージOSのバージョンアップに伴って発生したAPD障害についてご紹介できればと思います。
本記事の内容
それでは、よろしくお願いします。
背景
ESXiホストからマウントしているNFSデータストアを提供しているストレージ機器においてOSバージョンアップを実施しました。
バージョンアップ作業は3段階で、冗長化された2台のコントローラに実施する必要があるため合計6回のバージョンアップ作業が必要でした。
残念なことに、その中の2回で通信障害が発生してしまいました。
それぞれの通信障害時間は以下の通りです。
各通信障害の時間
1回目:約2分程度
2回目:約20秒程度
この通信障害に伴って、ESXi側では複数のデータストアにおいてAPDが検知され、データストア切断と判定されたものもありました。
本記事では、そのあたりの情報を整理していこうと思います。
ストレージ側での通信障害の内容については、以下の記事にて紹介しているので気になる方は是非読んでみてくださいね。
関連:【NetApp】多段階のONTAPバージョンアップ対応で二度の通信障害が発生した話
APD障害に関する整理
APD検知について
そもそも「APD」とは「All Path Down」の略で、ESXiホストがマウントしているデータストアなどのパスが全て切断された状態などを指します。
裏側としては、ESXiホストがストレージデバイスに対してSCSIコマンドを発行した際に、応答がなかった場合に検知されるようです。
なお、APDとして検知されるまでの「判定秒数」については、残念ながら公開されていないようです。
関連:vSphere 6.x および 7.x での永続的なデバイスの損失 (PDL) と全パス ダウン (APD) (2004684)
今回のケースを例にしたAPD発生時の処理の流れ
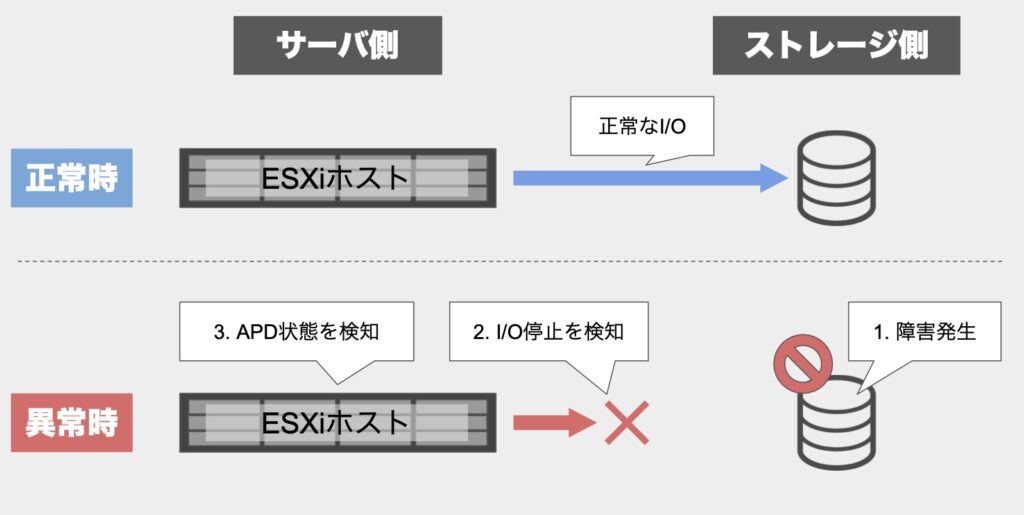
今回のストレージ側でのOSバージョンアップに伴ったAPD発生を例に、一連の流れを整理してみます。
APDは発動後、「Misc.APDTimeout」という設定項目での指定秒数(デフォルト:140秒)までにI/Oが復旧するかどうかで、データストアのステータスは以下の2パターンに分かれます。
Misc.APDTimeoutとは何者か?
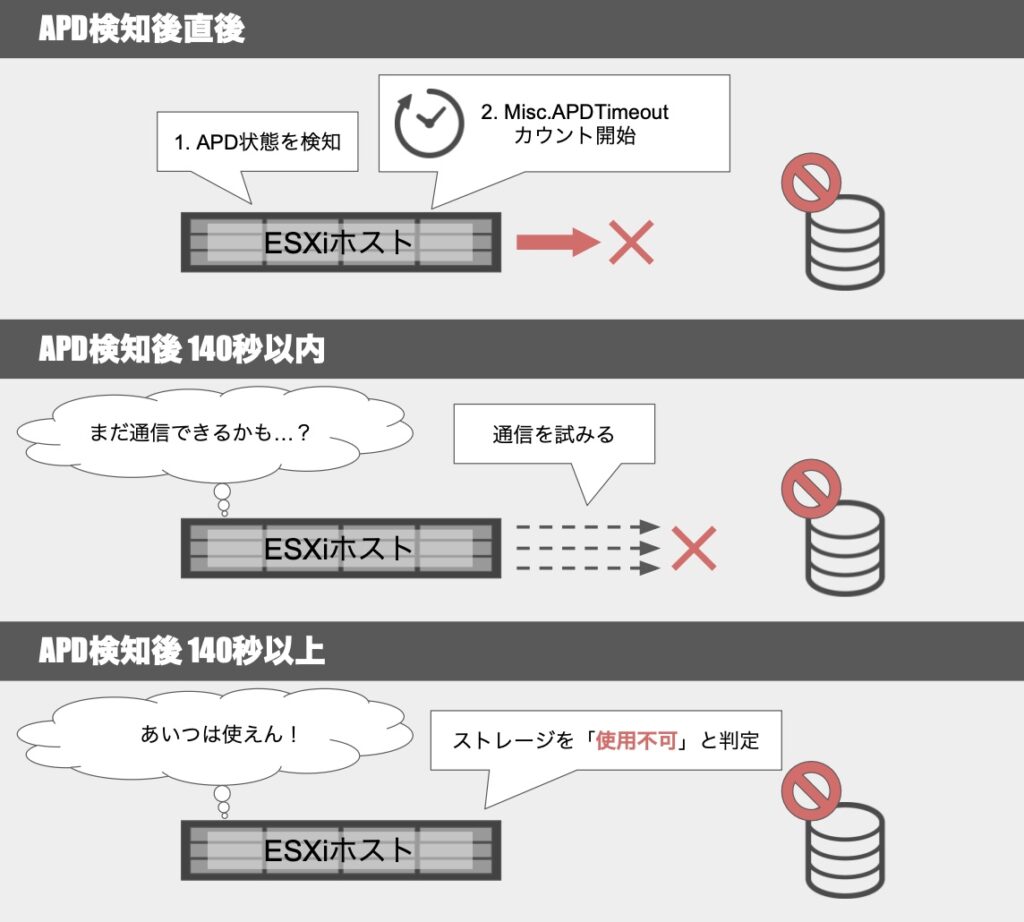
Misc.APDTimeoutは、APD発動後のタイムアウト制限を設定する項目です。
APD状態になった後も、ESXiホストは本項目で指定した期間はI/Oコマンドの再試行を続けます。
しかし、指定した期間が経過しても復旧されなかった場合に、ESXiホストはAPD状態のデバイスを「使用不可」としてマークし、I/O再試行などを終了します。
なお、その期間の仮想マシンからのI/Oは一時的に保留するものと思われます。
もしストレージとの疎通が再開した場合には、保留していたI/O処理も再開する模様。
参考:ストレージ APD のタイムアウト制限の変更
参考:一時的なAPD状態の処理
今回のその後
今回の作業環境では「Misc.APDTimeout」はデフォルト値の140秒が設定されており、幸いにも140秒以内にI/Oが復旧しました。
その後の動きとしては、データストアも自動的に接続状態に戻って、通常稼働状態に復旧となりました。
なお、もし140秒以上経過して「使用不可」状態になってしまった後にストレージ側が復旧した場合にはどうなるのか?をベンダに問い合わせてみました。
結果としては、データストアの明示的な再マウントなどは不要で、自動的にデータストアも使用可能になるようです。
APDとは別の「データストア切断」に関するイベントログ
2回発生した通信障害の内、「データストアの切断」に関するイベントログが1回目は出力されて、2回目は出力されなかったのが気になりました。
全量ではありませんが、「APD」と「データストア切断」に関するイベントログには次のようなものが挙げられます。
APDのイベントログ
[出力例]
識別子xxxxのデバイスまたはファイルシステムが「すべてのパスがダウンしています」状態に切り替わりました。レベル:警告
時刻(例):2023/12/1 10:56:35
データストア切断のイベントログ
[出力例]
サーバxx.xx.xx.xx(マウントポイント /ボリューム名、 xxxxxxxx(データストア名)としてマウント)との接続は切断されました。レベル:エラー
時刻(例):2023/12/1 10:57:59
勘違いしていたこと
調査当初は「APD発動 -> Misc.APDTimeout時間の経過(デフォルト:140秒)-> データストア切断」と思っていました。
そのため「APD発動からデータストア切断まで84秒しか経過していないのになぜ切断された?」と疑問が生じていました。
しかし、どうやら上記のAPDイベントログとデータストア切断イベントログは関連しない独立したイベントであることが分かりました。
つまり、データストア切断と判定する上での「開始時刻」は、上記のAPDイベントログの発生時刻(2023/12/1 10:56:35)ではなく、NFS Clientがストレージとの切断を検知した時刻だったんですね。
NFS Clientが切断と判断するまでの時間
NFS ClientはNFSストレージとの疎通確認として「Heart Beat」を利用しており、一定時間経過しても疎通が取れないと「使用不可」としてマークします。
なお、「一定時間」には「最小時間」と「最大時間」があり、それぞれ次のような式で算出することができます。
算出に利用される各項目は、ESXiホストの詳細設定から設定 / 確認が可能で、ESXi7.0におけるデフォルト値は以下のようになっています。
これらを用いて先程の式より「最小時間」を算出してみると「113秒」となります。
改めて1回目と2回目の通信障害について整理してみます。
| 障害時間 | APD検知 | データストア切断検知 | |
|---|---|---|---|
| 1回目 | 約2分(120秒) | あり | あり |
| 2回目 | 約20秒 | あり | なし |
1回目は約120秒の通信障害であったことから、先程算出した「ボリュームを使用不可としてマークするまでの最小時間(113秒)」以上であったことから、APD検知に加えてデータストア切断も検知されたと考えられます。
一方で、2回目については約20秒と比較的短め(113秒以下)であったことから、APD検知はしたもののNFS Client的にはデータストア切断とまでは判断されなかったと考えられます。
おわりに
いかがだったでしょうか。
今回はストレージOSのバージョンアップに伴って発生したAPD障害について整理しました。
APD発生の根本原因はストレージ側のバグだったのですが、今回の件でVMwareにおけるAPDについても学ぶことができました。
可能な限り障害には遭遇したくないところではありますが、学びが多いのも否定できません(笑)
もし遭遇してしまった際には、今後もブログを通して共有できればと思います。
本記事を最後まで読んでいただき、ありがとうございました。
ではでは!